

Redis的高性能和他的事件模型是密不可分的,最大程度上利用了单线程、非阻塞IO模型来快速的处理请求(单线程处理多链接)。这里存在一个问题,其实严格意义上来讲,Redis 是单线程对外提供服务,redis内部并不单线程的,还存在一些关于数据持久化的线程。
在这里我们主要看的是Redis 对外提供服务的线程,Redis 很大程度上得益于单线程、非阻塞、多路复用的IO模型,就具体实现而言,Redis依赖的是一个专一且强大的异步事件库(ea)。ae里面封装了针对不同操作系统的polling机制,比如epoll、select等。
简单的看一下这几种polling模式
文件描述符(fd):
在Unix/Linux系统中,可以粗暴的认为一切都是文件。对于内核而言,所有打开的文件都是通过文件描述符进行引用的,具体来说,内核用一个文件描述符来表示一个特性进程正在访问的文件,通常来说一个文件描述符的有效范围是0到OPEN_MAX,就默认来说每个进程最多可以打开64个文件(0-63),对于 FreeBSD 8.0、Linux 3.2.0、Mac OS X 10.6.8 以及 Solaris 10 来说,文件描述符的变化范围几乎是无限的,它只受系统配置的存储器总量、整型的字长以及系统管理员所配置的软限制和硬限制的约束。然后最大文件描述符数,Linux中进程最大打开文件描述符是1024,我们可以通过ulimit命令、修改limits.conf文件来进行最大数的修改。
这里需要注意一点容易被混淆的概念:/proc/sys/fs/file-max 并不是指最大文件描述符数的上限值。file-max指的是Linux内核分配的最大文件句柄书、file-nr是一个(已经分配的文件句柄数、已经分配但没有使用的文件句柄数、最大文件句柄数)的三元组。
然后来看一下常见polling模式对比:
select:
1 每次select都要把全部IO句柄复制到内核
2 内核每次都要遍历全部IO句柄,以判断是否数据准备好
3 select模式最大IO句柄数是1024,太多了性能下降明显
poll:
poll使用链表保存文件描述符,因此没有了监视文件数量的限制,但其他三个缺点依然存在。
拿select模型为例,假设我们的服务器需要支持100万的并发连接,则在_FD_SETSIZE为1024的情况下,则我们至少需要开辟1k个进程才能实现100万的并发连接。除了进程间上下文切换的时间消耗外,从内核/用户空间大量的无脑内存拷贝、数组轮询等,是系统难以承受的。因此,基于select模型的服务器程序,要达到10万级别的并发访问,是一个很难完成的任务。
epoll的特点
1 每次新建IO句柄(epoll_create)才复制并注册(epoll_register)到内核
2 内核根据IO事件,把准备好的IO句柄放到就绪队列
3 应用只要轮询(epoll_wait)就绪队列,然后去读取数据
只需要轮询就绪队列(数量少),不存在select的轮询,也没有内核的轮询,不需要多次复制所有的IO句柄。因此,可以同时支持的IO句柄数轻松过百万。
很显然,epoll模式是就当前来说最适合应对高并发访问的,epoll是这样工作的:
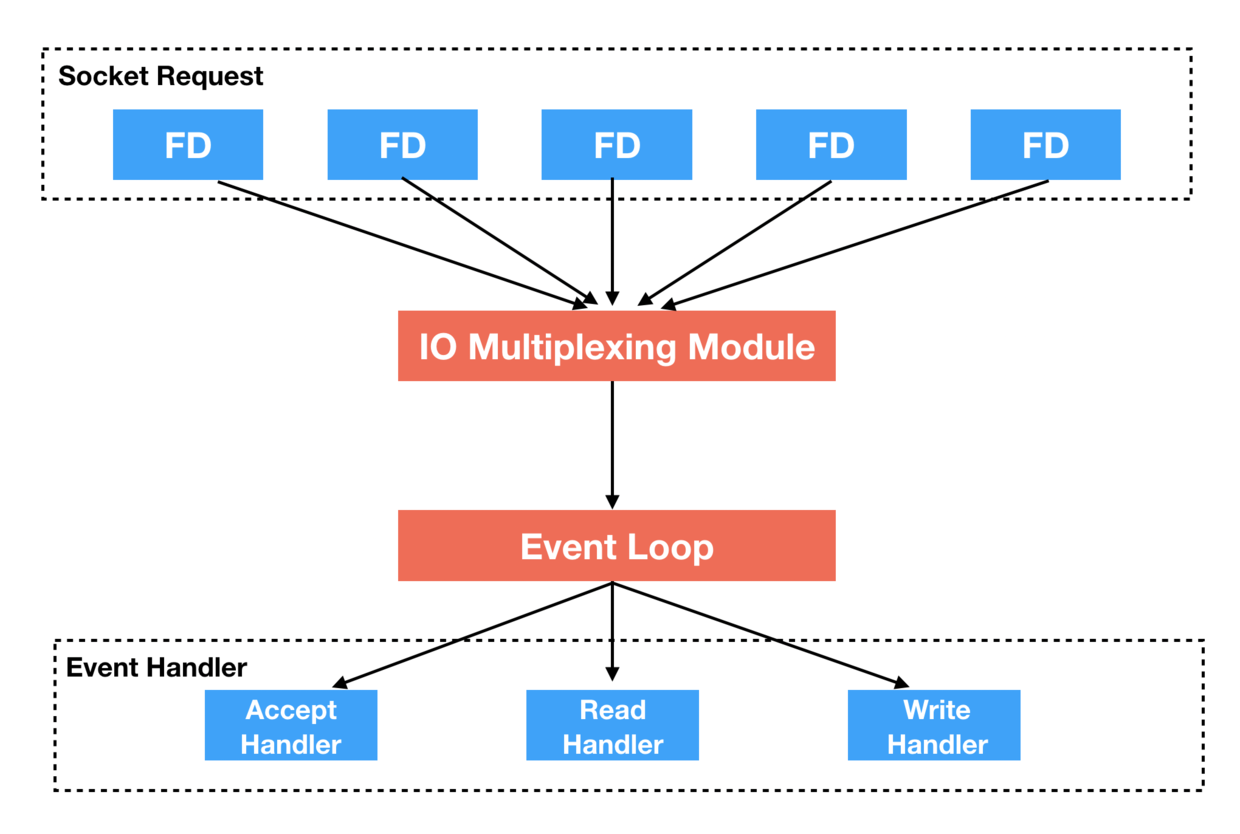
1、调用epoll_create 通知kernel我们要使用epoll
2、调用epoll_ctl把fd和关注的event传给kernel
3、调用epoll_wait等待该event的发生
4、fd被更新时,kernel向应用程序发送通知。
所以说有了epoll替我们做这些事儿,我们仅需要关注事件处理函数、回调函数就OK了。
下一篇看一下Redis中对于这种模式的实现。

