

前言
大家在观察压测&日常线上请求的平响、cpu使用时通常都能见到n多的毛刺,有的毛刺凸显并且有规律可循,有的杂乱无章,这些毛刺到底是因为什么产生的,对应的解决解决套路是怎么样的?
排队和并发
说毛刺之间先来看一下cpu工作的模式:排队和并发,并发指的是我们在某一时刻同时处理多个任务,而排队是指对于cpu而言任务调度处理的机制。这两者直接决定了任务处理的时延,落到用层面也就是我们的用户体验。 认知cpu底层性能的工具和方法有很多种,如果之前没有相对清晰的认知可以看下这篇文章: https://zhuanlan.zhihu.com/p/213720319 https://zhuanlan.zhihu.com/p/142284880
cpu毛刺
cpu毛刺通常是某时间段(相对较短)cpu消耗攀升导致的,cpu毛刺会导致很多很多不好的事情发生,比如:平响毛刺、任务挤压、缓存更新不及时等n种搞掉你服务可用性的事情,这些问题本质就是一开始提到的时延问题。 攀升的原因通常有这么几点:
大量消耗CPU的定时任务
我们代码中经常起几个线程定时刷一下本地缓存、ct任务定时检查下服务状态或者其他什么事、logstream基础设施,这类定时任务难免会占用cpu,如果这些操作中涉及大量RSA操作、正则过滤、IO操作 CPU瞬间升高是不可避免的,如果压测过程中没有碰到这部分任务,但是线上峰值来了恰好定时任务也执行了,服务可能就部分不可用了,所以在评估真实容量时一定要把所有的cpu消耗全部考虑进来。如果涉及到极端场景下的性能优化,就要考虑把这些东西给停掉保证服务器的纯粹,只干一件事,互不影响。
有人在搞事情
大部分公司线上机器的权限是收敛的不错的,能够限制在操作系统上操作的命令,但是也存在部分场景收敛不到位,或者即使收敛到位了,有人在正则&awk查一个1个G的日志文件也是有可能的。 这里最好的方式就是进一步限制,日志、脚本等操作可以统一收敛入口。
机器问题
我们无法保证机器是完全没有问题的,虽然这应该是op干的活,但是身为rd我们还是需要保持对于服务各种强依赖的不信任,就比如我们的服务器,很多快过保的服务器可能提前发生性能衰退,如果用容器的话,每次可能宿主机都不相同,这样的情况更要谨慎。
可预知但是没在意的工具逻辑
拿Java来说,我们在关注我们代码中相对耗性能的操作,比如说IO、RSA计算等,却时常忽略了进程中GC对于性能影响的占比,在常规流量情况下GC的占比可能也就1%以下,但是如果流量升高之后我们代码的“垃圾特性”就开始凸显了,动辄几个Full GC,整个gc过程的cpu消耗可能都会占到整个进程的cpu使用的50%以上。 拿Redis来说,导致redis cpu used飙升的hgetall、大key、lua脚本等,我们知道会导致cpu 飙升,但是觉着就偶尔几次所以没在意。 很多时候我们会忽略这些特性,觉着工具本身能帮我们解决或者我们无能为力,实际恰恰相反从一开始写代码我们就需要关注到并且深入了解我们所有的工具,向上到服务层面的影响、向下到cpu、内存的影响,对外到对于其他进程的影响。
耗时毛刺
耗时毛刺会直接影响到我们的服务可用性,分析解决问题通常也是从平响毛刺下手再到代码再到CPU、内存、带宽等最后重回代码来操作的。对于耗时,出现毛刺通常是因为在某一时间间隔内请求处理受到阻塞(包括连接处理的阻塞、连接内处理逻辑的阻塞),其中的主要的原因大概率是上面提到的cpu毛刺。
连接处理的阻塞
连接处理的阻塞往往意味着服务处理的极限,因为连接内部整体cpu消耗相对平均,由于cpu资源受限很多连接虽然建立了,但是部分请求迟迟得不到处理致使请求处理存在问题(不响应:502发生)或者处理时间十分长(毛刺产生)。 如果应用如果已经优化到极致了,可以理解为这种情况就是服务器的处理极限了,这时候解决方式只有扩容。如果代码还没有优化,那就先针对各种性能分析的profile优化代码吧,比如减少单个请求中要消耗的CPU、请求处理过程的耗时,针对IO处理的(尽可能不做、合并IO、同步改异步、使用更加高效的API),针对CPU大量消耗的(只能尽可能的不做或者替换代价小的操作方式,何种序列化操作、RSA操作通通干掉)
连接内处理逻辑的阻塞
这个情况的原因有很多:
Java、Go中的GC操作导致用户线程暂停
stw一直是GC算法中无法避免的问题,即使现在用写屏障、读屏障等钩子代码标记联动来尽可能减少stw的时间,但是最初的stw仍然无法避免,这是存在GC逻辑的语言中最大的痛,因为stw 期间用户线程完全是暂停的。 我们能做的只有 优化代码尽可能少的stw,根据场景选择选择垃圾回收器,适合的最好的。如果你写Java:ZGC、G1、CMS、parralell GC总有一款适合你,如果你写Go 不如看看bfe重写GC模块的案例。
下游响应较慢,但超时时间较长
很多时候平响毛刺并不直接因为我们服务的原因,下游耗时时间忽然增加,又恰好我们的超时时间又设置的很长,毫无疑问我们会随着下游的抖动而一起抖动,如果依赖的下游很多,我门这样随机出现毛刺的概率也会相应的提升。
某时段CPU消耗骤升
这一块的原因其实就是一开始说的cpu毛刺,某小时间段内的cpu使用率飙升我们的操作迟迟得不到处理或者处理缓慢就会出现大量的毛刺。
误用epoll的问题
这是一个很小的原因,但是很多时候线上出现的很长时间的无效链接、大量的接入层502可能就是这个原因导致的。 epoll(event poll)可以理解为是一个盒子收集缓冲区信号通知,内部维护了socket注册列表(epoll_ctl:红黑树)和一个就绪队列(epoll_wait:rdllist双向链表)对外提供事件通知,外部会拿到epoll_wait返回的就绪文件描述符集合,然后循环事件进行处理。
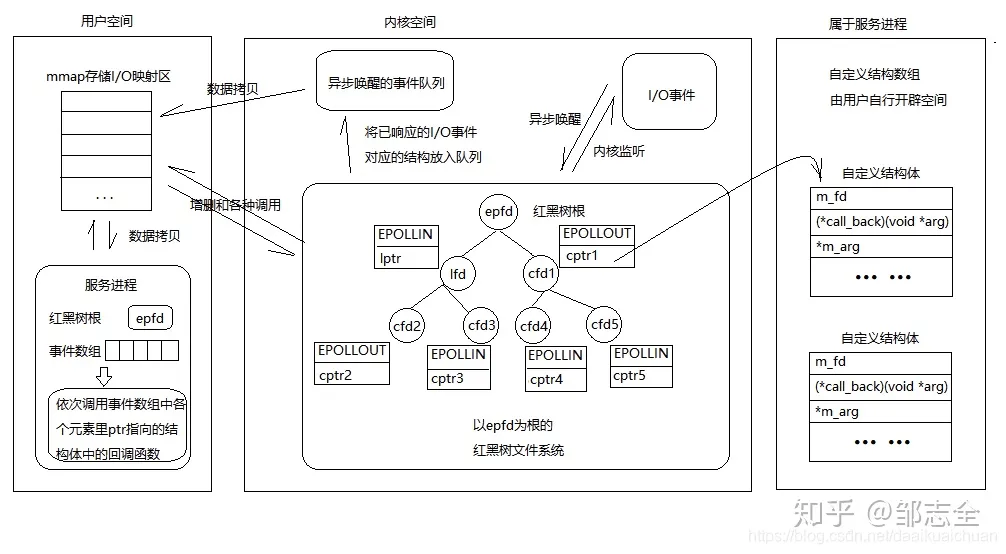
epoll有两种模式:LT、ET。LT水平触发相当于会只要可读、可写就会有事件给出。但是在ET边缘触发模式(条件触发)下,有数据到来仅通知一次(系统不会充斥大量不关心的就绪文件描述符,只返回新的)。
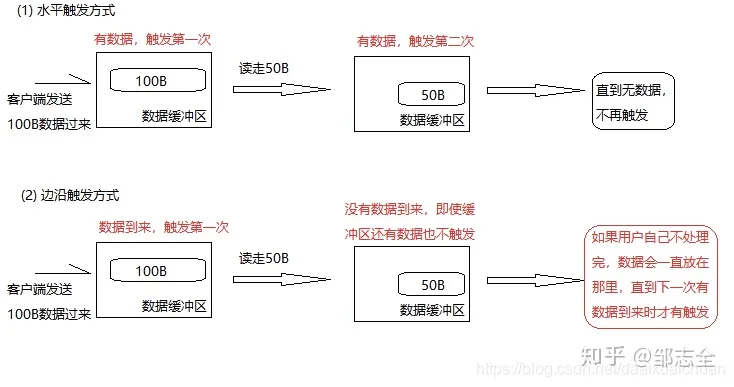
ET模式下: 有多个连接同时到达,服务器的就绪队列瞬间积累多个就绪连接,accept只处理一个连接,导致就绪队列中剩下的连接都得不到处理,可能会发生饥饿现象,导致一些连接始终到达不了出发条件而一直无法处理产生无响应状态,导致毛刺或者接入层502的产生。 还有一种情况是:文件描述符如果不是非阻塞的,那这个一直读或一直写势必会在最后一次阻塞。这样就不能在阻塞在epoll_wait上了,造成其他文件描述符的任务饥饿,导致无法处理。 remarks:图都是网上找的
定位问题
火焰图
在分析服务性能极限,优化代码性能时通常会用火焰图来打印各种profile来进行分析。 挂火焰图分析通常是压服务极限时使用的。( 常见压测的套路: 1、压服务极限(发现代码问题,优化现有代码) 2、压单机极限(用来评估整体容量,通常和第一步合并进行,cpu used 60%~70%) 3、压集群极限(按照目标峰值压测) 4、按照上述环节压降级 ) 直接贴几个工具吧: C :sudo perf record -F 99 -p 22645 -g — sleep 30 Go 语言:go-torch Java :https://github.com/jvm-profiling-tools https://github.com/brendangregg/FlameGraph 生成图片就可以了。
shell 命令
对于线上的应用火焰图可能不太合适,因为拉取cpu、内存profile的过程对于cpu、带宽消耗很多,所以通常就找一台机器用原生的命令拉取一下快照(也会有损耗但是还好) 通常来说: 1、top 看一下当前消耗较大的进程 2、top -p 拉目标进程分析单个进程内消耗情况 3、找到最大的线程 4、jstack 看一下对应的具体情况(如果是Java 应用的话)

