1. 前言
始前先看下整个文章的梗概:我会对于多变业务,比如“小步快跑”、“创新试错”下的业务开发模式和架构方案做出分析设计,最终推导出Faas + ServerLess架构,并就Java技术栈下,对于这种架构进行落地,实现基于自定义Groovy引擎的Faas+ServerLess架构下的“低代码”服务。

1.1 大体背景
我由于是做营销活动相关的,日常经常会碰到一个场景:各种频出的创新的idea需要尝试,创新这件事儿意义很大。但是每个idea都去实践落地,成本又太高了,如果完全靠直觉和经验,很容易扼杀一些优秀的idea。
所以就开始尝试降低创新的成本,比如说之前一个活动30人日,我们能不能降低到3人日,看上去这是一个很夸张的成本节省数量,但是理论上是可行的。
1.2 成本分析 – 需要提效
首先我们对于成本进行初步分析,一场活动的成本,大致分为:人力成本 + 活动预算 + 流量成本。
对于idea的创新实践,我们初期并不需要过大的活动预算和大规模的资源流量,通常在前几天就能把效果论证出来,定向推送特征用户就好了,有传播倾向的idea,可以用延迟发奖来解决,效果好了就增加预算,效果差,钱也花不出去。
所以剩下的,最核心的成本在于人力成本,人力成本可比大家想象的要重要的多,尤其是在这么个降本增效的大环境下,几十人日、几百人日的投入创新尝试是不现实的,所以我们要解决的关键性问题就是活动生产的效率问题。
不仅是活动方面,其实每个具有创新属性、小步试错属性的场景,都有着类似的问题。
1.2 其他推荐
前面有几篇文章已经提到过大致的方法论和初步的实践思路了,有兴趣也可以前置的读一下,不过不读也不耽误本篇的阅读,部分内容是有一些重复的。
接下来进入正题,如何解决这种创新类、小步试错的“轻业务”。
2. 可以有的思路,一通分析
要想节省成本,有两个思路:减少工作量、提升落地效率。
事情得做,还得做作,需求不能砍,所以剩下的方法只有复用;提升落地效率,这个prd效率、前后端研发效率、测试效率每一个方面其实都可以去节省。

我们就idea的落地流程,进行细节上的分析,看看如何来提升效率。
2.1 落地分析
首先就整个流程进行分析,减少繁琐的流程,少一点大公司病,多一些创业状态,高生产效率的节奏下,快速idea落地体验,沟通对齐,是整体的目标。
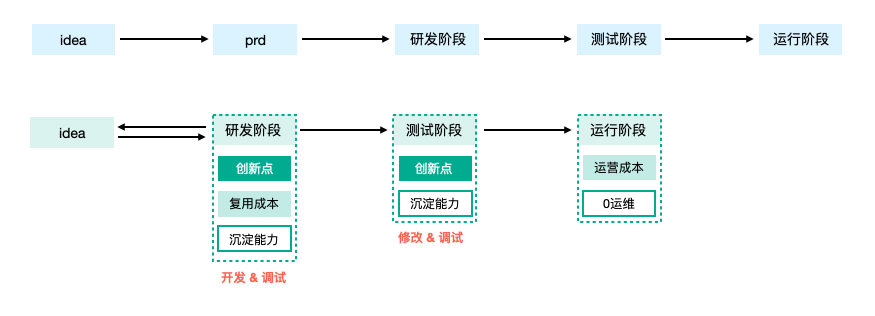
做事前,先看最佳实践,一种好的、理想的方式是“我只关心本次创新的部分,也只需要执行本次创新的部分”
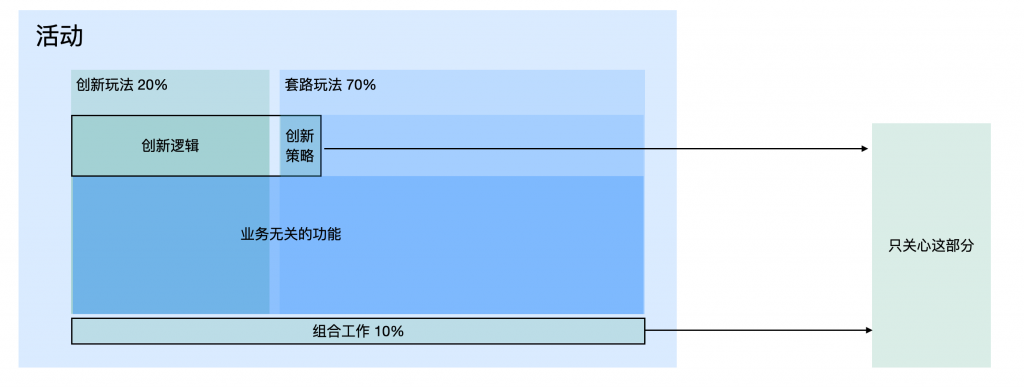
具体举措:
1: 要有机制能够保障只需要开发创新点,并且高效的开发创新点。
2: 影响能够隔离,只影响当前的创新尝试(测试范围),不影响其他任意功能或业务。
3: 线上无运维成本,即写即跑,不用申请存储、不用配nginx、不用起机群、不用部署上线,就小成本快速出个看板,关注具体效果就好。
4: 开发体验上,热更热部,0等待成本,大脑无线程间切换,快速心流模式。
5: 很轻松的就能复用,少量的复用适配成本。
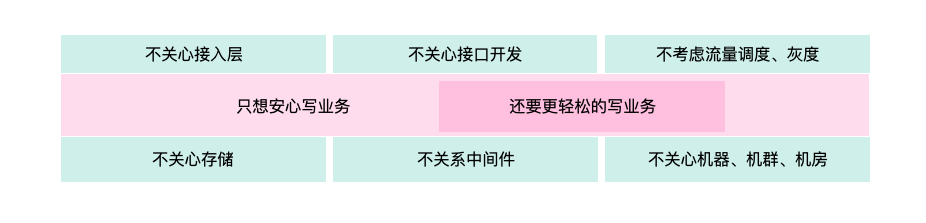
2.1 落地分析,我能想到的方案
2.1.1 开发过程
根据上面的最小实现原则,我们不妨对于开发一个功能所涉及的工作进行分析,就拿营销活动来看,我们能想象这么几种方案:
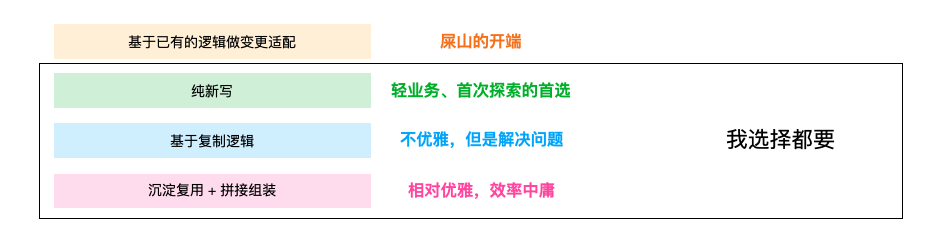
- 基于已有的逻辑做if-else变更
我们使用现有的活动做变更,支持给活动增加活动id之类的概念,用于区分不同的逻辑,在原有的逻辑上做新增,然后适配兼容。
这种模式就本次开发和之后的维护成本来说都是最高的,可能改起来最不费劲,加一点代码就解决了,但兼容逻辑、废弃逻辑会越来越多。我们业务上的屎山通常就是这样出现的。
而且对于单次活动的开发,影响面也没有控制住,可能会对既有逻辑产生一定的影响。
这个方案基本上可以否了。
- 完全纯新写
新起一组逻辑,完全用来支持当前的创新活动,与现有逻辑完全隔离,最小原则实现,和原有的逻辑完全做了隔离,这是业务发展初期、系统重构常用的思路,在成本不高的时候,是可行的。
但是如果逻辑相对复杂,创新idea的成本是没有减少的,所以这个方案也暂时先否了。
- 基于复制逻辑
copyOnWrite,把当前的代码做一份复制,在复制出来的代码上做修改,与现有逻辑变相隔离,不用适配老逻辑,直接做新增修改即可。
这样是不是就做到了,即跟既有逻辑隔离,又减少了重复开发。但是现实是我们的活动开发并没有那么轻松就可以复制,整个的复制成本也会很高,除此之外,老逻辑修改至逻辑的成本还是太高,需要对老逻辑非常熟悉才行。
要是有一种方式,能够一键复制就好了,比如就一个脚本,直接copy?这个思路没准能行。
- 基于沉淀复用 + 纯新写组装逻辑
我们去沉淀大量的工具,在创新idea到来时,利用工具集去构建新的活动,由于沉淀的这部分是稳定的,变的通常是组合逻辑,是可行的。
但是组装逻辑也相对庞大,能不能再省省。
小朋友才做选择,大朋友选择都要,我们想要的已经清晰了:快捷复制 + 纯新部分新写 + 沉淀功能集
2.1.2 调试过程
还记得写php和python的爽感嘛,语法精炼,热更热部。那能不能对于这种创新idea我们也采用这个技术栈,当然是可行的。想要提效,热更热部是必须的。

但是通常这个方式会收到各方面的制约,比如说技术栈不统一的问题,由于生态的原因,不得不否认Java是最主流的业务工程开发语言。并且对于活动场景来看性能要求是比较高的,php、python的性能说实话,还是差了一些的。
我们需要一种模式提供热更热部,并且执行效率至少跟Java差不多,能兼容现有的功能集合语言上无缝兼容(如果调一个功能就来次rpc,成本太高了),顺道还能有Java的巨大生态便利。
肯定有人杠,Java也能热更热部,我是觉着真的够难用,而且跟这种天然热的脚本类语言完全不是一个概念。
2.1.3 运维成本
开发、调试完成、测试完成之后,下一步就是线上运维了,传统的开发模式,研发对于线上的机器资源、存储资源、中间件资源等感知太多了,但就一个上线过程就要耗费掉一天的时间,并且为了安全还要使用各种手段,一台台机器去灰,还要感知nginx、DB等中间件服务,需要时还得有各种前置工作。
那能不能无需感知这些对于线上应用即写即跑,背后的资源毫不关心,让研发看不到“机器”,管控该做做,灰度就用流量灰。
2.2 Faas + ServerLess
把上面的方式总结下来看:
- 开发过程
- 快速复制
- 稳定的功能集合
- 调试过程
- 即写即跑,热更热部
- 运维过程
- 不感知服务器
总结下来这不就是Faas和 ServerLess架构嘛(面向的沉淀好的稳定功能集合,进行脚本化编程)。我们只需要给我们的系统,增加能执行创新idea的容器就好了。
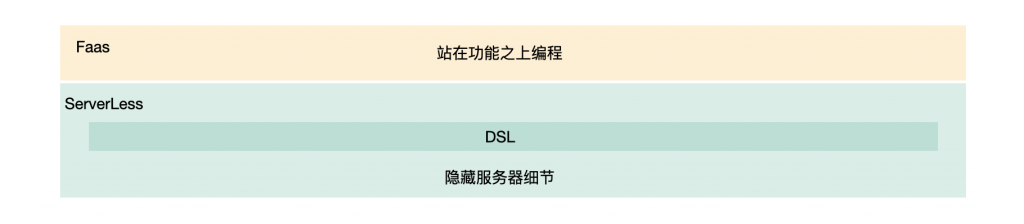
用脚步写几个基础活动模版,然后实例化一个模版(复制一个出来),把创新的玩法在里面加进去,编写创新玩法时,使用我们沉淀好的功能集合,发布时就点一下,然后自动构建接口,自动识别存储。需要灰度就拿流量整个白名单推全,然后在整个脚本的版本系统,是不是问题就都解了。
整体的方案就是这么简单,但是我们需要解决落地过程中的 Java兼容性问题、脚本对于功能库的识别、高效复用问题、脚本执行性能问题、服务稳定性问题,下面就具体来看,是怎么落地的。
业界并没有一种完美的解决方案能把上面的几个问题妥善解决掉,在整个落地过程中做了较多的自主优化。
3. 基于Groovy引擎的优化落地
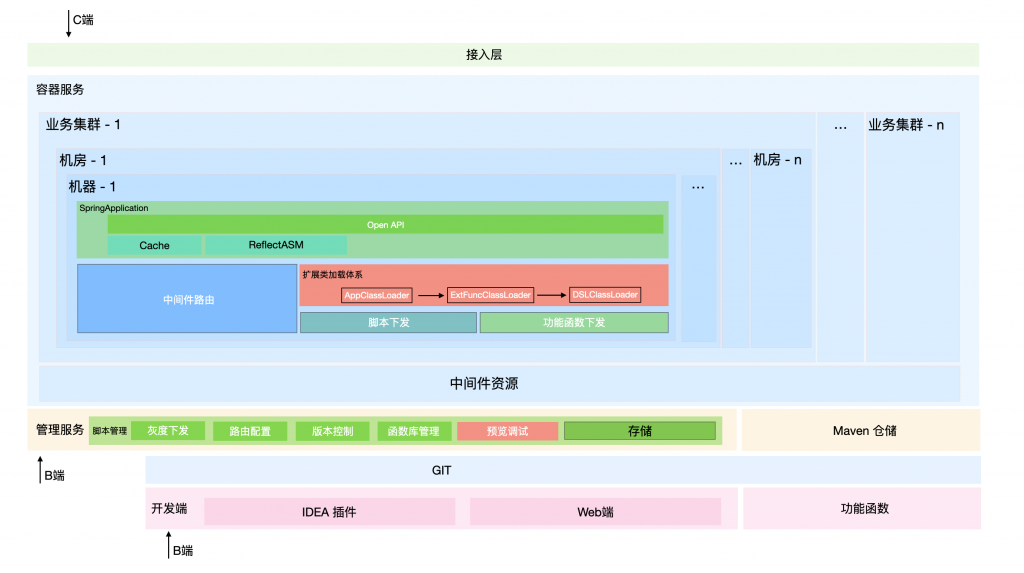
直接看下我们要落地的应用:
3.1 Java 兼容性问题
这里就拿业界最常用的Java技术栈来看落地,其他场景可能技术选型不同,但是思路是一致的。
Groovy算是Java生态中最常用的语言了,纯粹的groovy语法十分精炼。并且与Java环境高度兼容,甚至可以直接在groovy脚本中写Java代码。
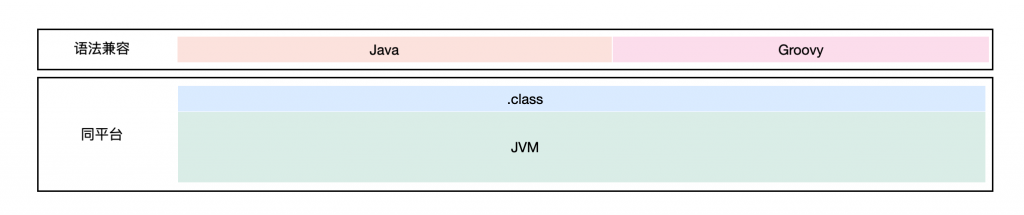
在国内Groovy 最常用的场景是写单测脚本、写离线数据脚本等等,很大的原因就是跟Java兼容性极高,并且编写效率极高,对于Java开发同学没有成本。
但是Groovy脚本性能是比较差的,测试来看比Java性能得低一个数量级,无论是用哪种执行方式,这个是脚本执行的通病,但是如果把性能问题解决了,Groovy脚本是不是就很香了。
3.2 脚本执行性能问题
Java环境中使用groovy脚本有这么几种模式:GroovyShell执行、GroovyClassLoader、GroovyScriptEngine 三种方式去执行脚本。这三种模式都是类似的,性能都比较差。
3.2.1 执行原理

- GroovyShell
GroovyShell 适用于执行片段脚本,具体执行过程,可以理解为把代码片段放到一个静态方法里,然后invokeStatic,然后完成处理。
每次都要进行新groovy 脚本的拼接,然后编译成对应的class文件,然后再newInstance构建一个对象,然后向下转为GroovyObject,然后调用invokeStatic。
整个拼接、编译、反射调用都是非常耗时的,然后次次编译产生大量的类,短时的方法区占用比较多。
- GroovyClassloader
GroovyClassloader 可以选择groovy文件进行编译,然后夹在对应的class文件,使用的方式也是newInstance对象,用GroovyObject中的invokeMethod方法,调用的是MetaClass中的invokeMethod方法,最底层就是lang.reflect,性能也比较差。
相对于Groovy少了拼接、编译的过程,我们可以根据需要缓存对应的实例,每次的主要成本就是反射调用成本。
- GroovyScriptEngine
这东西就是在groovyClass、GroovyShell上封装了一下,可以指定url去进行当前目录的脚本访问,并且提供了缓存机制,能自主发现文件更新(检查md5),提供了使用上的便利性。
但是这些便利性还不如不提供,反而引入了OOM风险,方法区不会进行卸载,然后每次变更会生成一个全新的class。并且性能方面虽然提供了缓存,但是反射调用的问题依旧无解,性能还是比较差
3.2.2 基础信息供给
回忆点基础,设计过程需要大量的类加载、反射等相关知识。
一个class对象的唯一标示是:类加载器 + 类全限定名称。
一个class文件被装载后在方法区生成class对象(启动时),这个对象在整个运行过程中是无法被替换的,像重新加载要么换名字,要么换类加载器,要么改JVM(这个侵入性太大)。
Java的类加载委派模型,最上层是bootstrap、然后是Extension、在是application,然后加载时会层层向上委派,主要是解决同一个类不同加载器问题。
由于上面的实现,父类加载器加载的类,是没办法访问子类加载器加载的类的,这个隔离是在class文件装载时进行校验的。
反射定义 是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性;这种动态获取信息以及动态调用对象方法的功能称为java语言的反射机制。
有了前置的这部分信息,我们开始进行分析设计。
3.2.3 自定义引擎
针对性能差的问题,我是做了对应的自定义实现,反正就是个编译 + 装载的过程。并且除性能以外,我需要对于整个过程都完全可控。
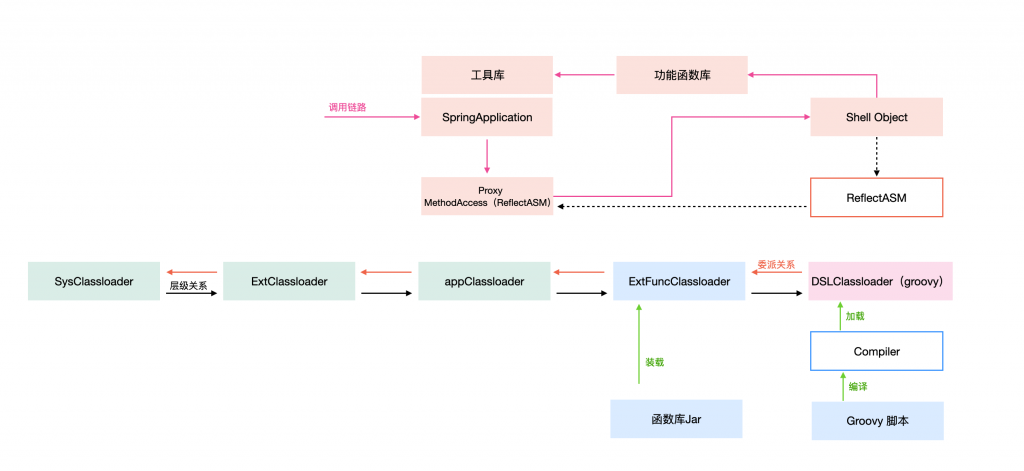
首先使用CompilerConfiguration进行脚本编译控制,编译成对应的class文件。(这里可以让编译过程可控)
然后自定义classloader进行装载(只需要一个单纯的class文件,只需要一个装载功能,并且需要整个过程完全可控)
然后ASM 进行对应目标class的代理类生成(ReflectASM),生成新的class:*****MethodAccess,然后再用代理类完成Groovy 脚本内方法反射调用(由于直接定位到方法调用,本质就是直接调用)。
过程按照一定的策略缓存对应的代理对象,来避免次次编译、创建代理。
这样使用grovvy的时候,就跟使用本地方法一致了。
ps: 为什么ReflectASM比Java原生的反射快,而ASMReflect比直接调用性能差在哪,为什么能得到JIT的优化,下面尝试分析。
- 直接调用
前置动作:java 代码 -> 字节码 -> class load
执行时:根据加载好的类信息找到对应的方法引用,去执行就好
- Java 原生反射
前置动作:java 代码 -> 字节码 -> class load
提前缓存:获取class信息 -> 获取对应Method
执行过程:检查系统状态和参数可以执行这个方法 -> 和正常JVM执行方法一样执行这个方法
- ReflectASM 反射
前置动作:java 代码 -> 字节码 -> class load
提前缓存:获取class信息 -> 生成XXXXXXXMethodAccess类 -> 完成新类load
执行过程:使用向上转型后的代理对象(MethodAccess容器加载可识别)-> 调用invoke方法 -> 然后会走到具体的实现类(继承自MethodAccess)-> 然后代理内部将脚本对象强转为对应的脚本对象 -> 根据名称(for-each)或者方法序号(switch-case) 对于脚本对象的方法进行直接调用。
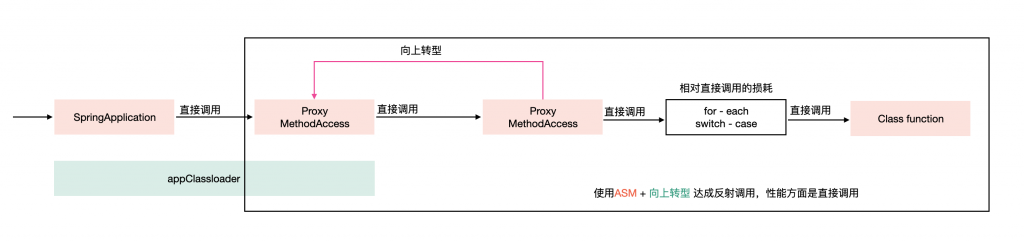
ReflectASM进行调用比直接调用就多了两层栈、一层for-each或者switch-case,性能近似相同。
ReflectASM相对于原生JDK的反射,基本相当于直接调用和反射调用的差异,少了参数和状态检查的过程,并且能得到JIT的优化。
ReflectASM能被JIT优化到,完全是因为这种模式本质上就是直接调用。
看上去父类加载器访问了子类加载器加载的类,其实没有,装载过程都是没有任何问题的,这里就是利用了向上转型,编写时使用父类进行子类访问,然后再层层向上使用。
3.2.3 编译优化 – 内部函数链路优化
重写完引擎之后,发现性能还是差一些,然后一边压测一遍看了下对应火焰图,发现调用栈里多了一些我不认识的东西。并不是常规的函数调用栈。
这里的问题是因为Groovy的动态性,grovvy编译后的class对象都默认实现了groovy.lang.GroovyObject(可以尝试反编译上面的class文件看看哈),里面有一个MetaClass持有了整个类的元信息,方法路由就是通过MetaClass来进行方法寻找的,可以用这个机制完成在运行时完成属性和方法的添加。(底层调用其实就是反射,只不过让反射的使用变简单了),具体可以去看下官方文档哈。
这个动态性使性能大幅度下降,这时候我们就需要把这个特性给关掉:@CompileStatic 就行。
ps-1: 外层依然有必要进行动态代理,没有其他的入口,防止JIT中断。
ps-2: 很多时候JIT 去优化就是因为反射,具体可以看下对应的JIT 日志,-XX:+PrintCompilation -XX:+CITime
3.2.4 服务预热优化
我们日常的服务在启动时都会有预热动作,让服务的刚开始的请求都能以正常的性能来提供。但是容器化之后,新脚本的预热是缺失的。
预热缺失在除了会导致部分请求的平响增加,在流量极大的情况下是非常危险的,预热产生的开销和链接夯死有极大的概率导致服务奔溃,这里可以参照《架构视角的性能优化》
一个脚本中需要预热的是:client(初始化)、函数(实例化)、自身代码,核心重开销的是client、函数,自身代码的JIT热度其实还好。
这里可以给脚本的下发过程做一点处理,提供预热入口,编写脚本时就能保证脚本是热的。这样可以根据脚本的内部逻辑进行针对性的预热,但是这样相对麻烦,我们需要感知发布逻辑,并且每次需要新增代码,不够优雅。
最佳的方式是,服务启动时保证脚本中用到的函数、client这些都是热的,剩下的只有脚本逻辑了,这部分本质上的性能损耗非常少了,基本可以忽略不计。如果想要极致的优化方式,可以使用AOT编译,强制静态编译,这部分内容未曾实践落地,就不说了。
3.3 如何识别功能函数库
我们基于Faas落地组装逻辑,如果在开发过程中、运行过程中识别函数库呢。
首先功能函数库,可以有两种落地形式,标准的服务(有状态函数)或工具服务(无状态函数),就使用场景来看有状态函数是我们最常用的,比如说库存、机会、计数、榜单这些,工具函数比如概率、规则引擎、决策服务等等。
3.3.1 编译时 – SDK引入
3.3.1.1 服务引入
对于开发过程,由于是脚本 + 面向接口编程,可以直接利用类似于SPI的实现机制,引入一个SDK,只感知具体的接口,这个接口怎么实现、有哪些实现就由容器和运行环境来决定。
3.3.1.2 自定义函数库
除了上面的这种方式,可以直接跳过接口,直接自己导入沉淀好的工具库,比如一个Jar包,里面包含了自身的业务功能函数等等。
3.3.1.3 RPC接入
可以向在Java开发一样,直接在脚本里使用其他的RPC服务,只需要包装个类似于ClientFactory就可以啦。
3.3.2 运行时 – 类加载模型扩展
上面提到的都是各种开发时的引用方式,但是运行时怎么保证你的脚本们正常加载到对应的函数、容器又是怎么执行你的脚本呢。
我们spring中的包是在application这一层所加载的,相当于容器的信息是application加载的。
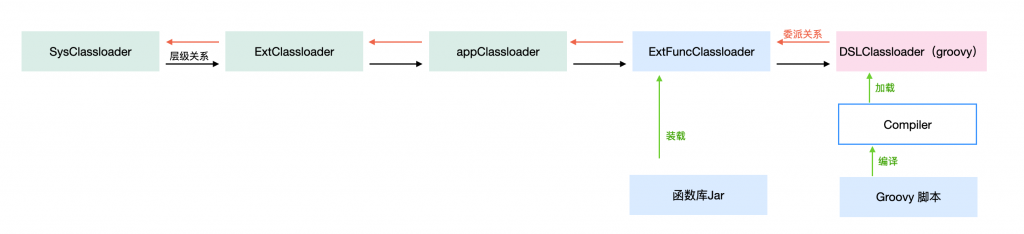
3.3.2.1 脚本识别
而脚本是子类加载器所加载的,我们想要访问,只能通过反射。(容器不感知脚本也非常的合理),所以就直接反射调用了。
不过这里绕了一层,直接通过ASM生成字节码文件,做了层代理,生成代理类之后,使用被代理类的加载器(脚本类加载器)作为父类加载器构建一个子类加载器,然后代理类通过子类加载器进行装载,最终会委派至父类加载器装载,也就是脚本类加载器装载。
具体可以看看,com.esotericsoftware.reflectasm.AccessClassLoader#get,逻辑不复杂。
ps: 调用过程可以认定是反射调用,但性能是直接调用
3.3.2.2 脚本访问容器
而脚本中想要访问存放于容器中的接口畅通无阻。
3.3.2.3 脚本访问函数库
然后再把自定义函数库加进去,只需要指定函数库Jar类加载器的父类加载器是application就好,然后再指定脚本的父类加载器是函数库Jar类加载器即可。
这样就做到了,脚本中能够正常访问容器中的能力,又能访问函数库中的资源,同时容器能够正常访问对应的脚本资源。
3.3.3 整体来看
整体盘下来,类加载视图长这样:
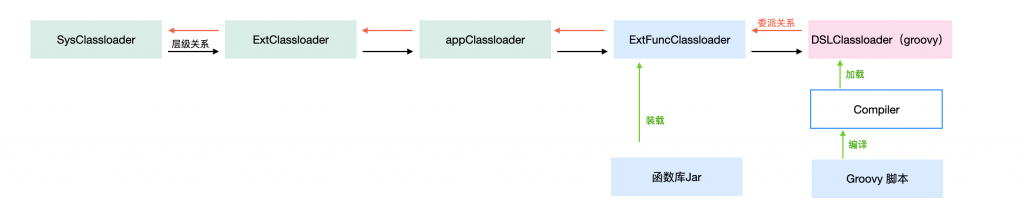
整体的调用链路长这样:
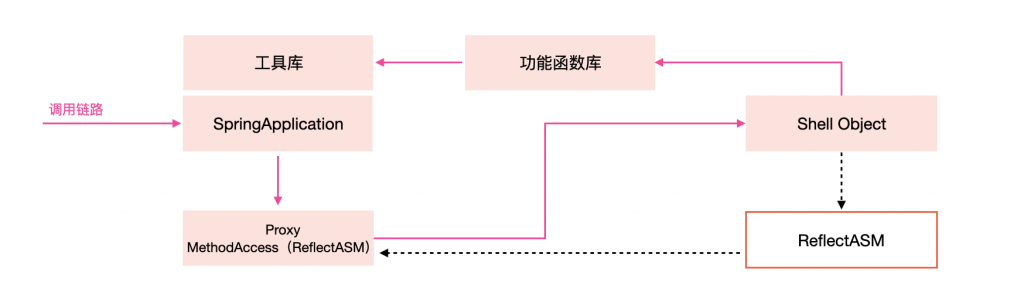
3.4 服务稳定性问题
解决完性能、兼容性、函数库识别之后,下一个问题是稳定性问题,要求其实很清晰,隔离性 + 故障屏蔽
3.4.1 隔离问题
脚本之间不能互相影响、不同业务的脚本之间不应该出现资源抢占的情况。
首先脚本之间在上面说的那种模式落地之后,隔离逻辑非常好做,只要把整个脚本try掉就好了,无论任何错误不能导致影响容器运行。
然后业务之间的脚本是互相隔离的,在一个资源上只能加载一个业务的脚本,或者只能加载其中一个脚本,必要时一个集群仅运行一个脚本也是十分有必要的,选择不同的套餐就好了。
并且应该对于单个脚本进行逻辑隔离的治理,比如说这个脚本能使用多少存储、能用多少机器、最大多少流量,只需要在存储选择层面做合适的集群转发、流量入口处做限流、分发至不同的集群即可。
3.4.2 故障屏蔽
当一个脚本存在技术上的问题时,是不应该被发布成功的,在新脚本错误期应该保持当前可用脚本对外提供服务。并且在错误期间应该持续性报警,并且脚本发布流程夯住的。实现模式就是经典的上线单发布流程。
对于业务性问题,我们是无法立即感知的,我们需要提供灰度过程,实现白名单用户、特征用户访问新的脚本,实现脚本的影响范围控制,如果小流量存在问题时,应该要有故障恢复能力。
3.4.3 故障恢复
提供脚本的快速回滚机制、脚本下线机制,在出现问题时能够快速的恢复。
3.5 复用的效率分析
可以参照我之前的文章营销活动提效之道,这部分内容为节选篇章,原理都是一致的。
3.5.1 颗粒度问题
通常来说复用机会和颗粒度大致呈负相关的关系,颗粒度越大,能够复用的机会就越小,颗粒度越小,能够复用的机会往往越大。
拿一个活动来说,从大颗粒到小颗粒,可以大致分为活动、玩法、有状态函数、无状态函数、库函数。
颗粒度越大成本节省越多,但是复用机会较小,颗粒度越小能够节省的成本越小,但是复用机会较大。就实践而言,单就成本节省带来的提效是有一个最优点的,这个点往往是有状态函数和玩法。那么我们复用的粒度基本就是围绕这个展开的。
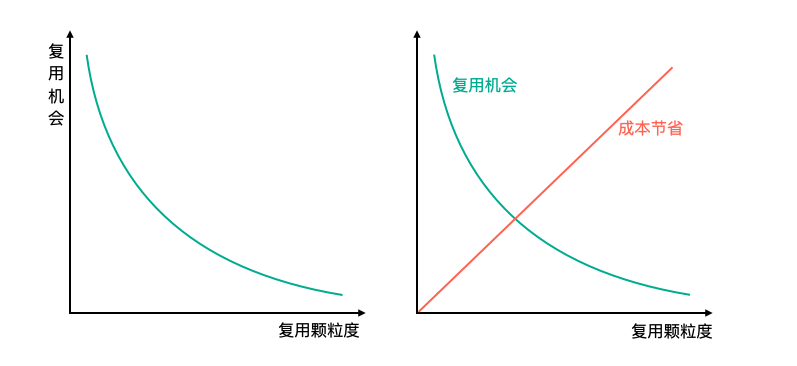
一场活动原封不动的直接复用几乎是不可能的,至少得换个皮吧,玩法复用机会明显大了很多,比如说抽奖、任务、签到等玩法复用,组成玩法的有状态函数复用机会就更大了,比如说机会、代币账务、库存、计数等等,再就是无状态函数,最后拆解到库函数,所有编程行为都是在这之上发生的,几乎完全复用。
3.5.2 创新限制问题
衡量出成本节省之后,我们不能单单按照这个进行执行,我们应该加入整个复用方案对于活动创新上的限制的影响。颗粒度越小对于创新时的限制是越小的,所以尽可能围绕最优的复用粒度偏向小粒度。
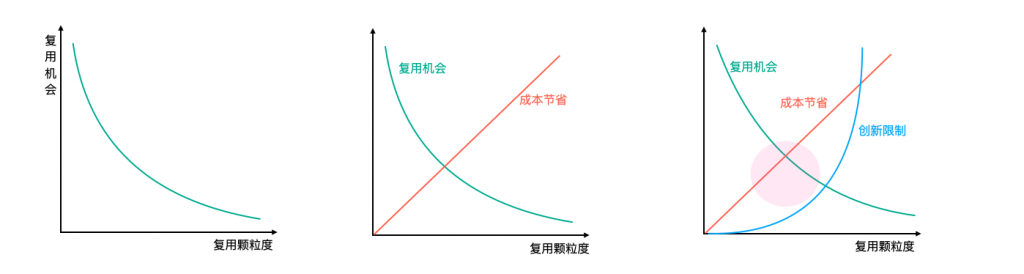
就实践而言,颗粒度到达有状态功能函数之后,就基本没啥限制了,所以最佳的复用粒度往往就是这个。
3.5.2 善用组合拳
前面一直在提创新的重要性,我们要做的是对于创新的提效。但是一场活动完完全全是创新玩法几乎是不可能,甚至完全全新的玩法对于用户并没有那么友好,通常是一个创新玩法带几个习惯玩法,这样才能做到让活动既陌生又熟悉,用户的体验才是最佳的。业界也基本都是这么实践的。

同时固有玩法的沉淀一样重要,这就要求我们的系统几个方向都得做,快速的玩法复用、快速的玩法变形、快速的创新玩法建设。
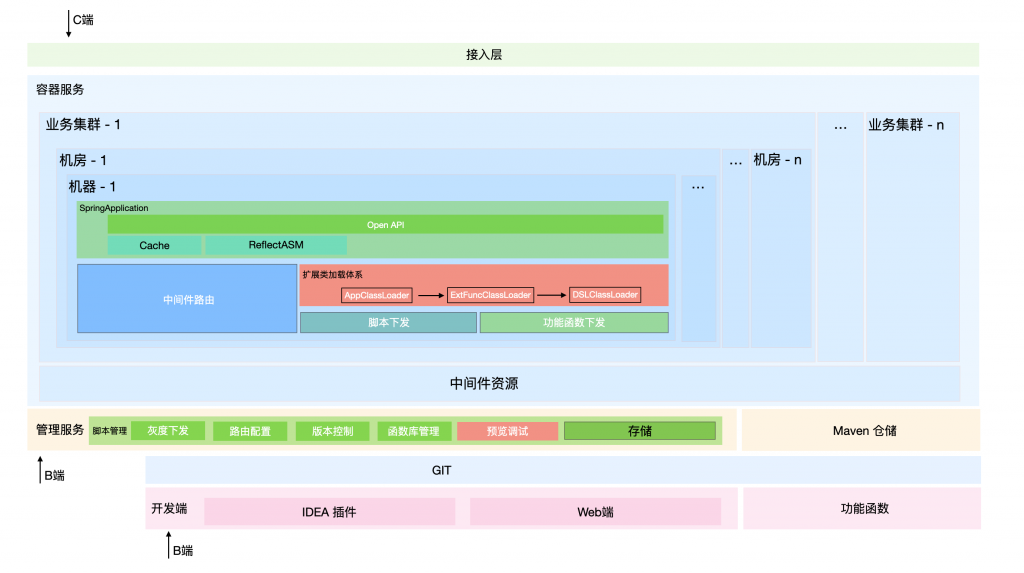
3.6 看下整体的逻辑视图
4. 一点启示
4.1 两万个配置问题
经常我们的会为了逻辑上的灵活性,增加很多的配置,曾经见过一些相对极端的代码,100行代码里10个配置项,如果发展到这样就没有必要了。
零散配置维护带来的成本远比灵活性带来的收益要大,ROI完全打不正。
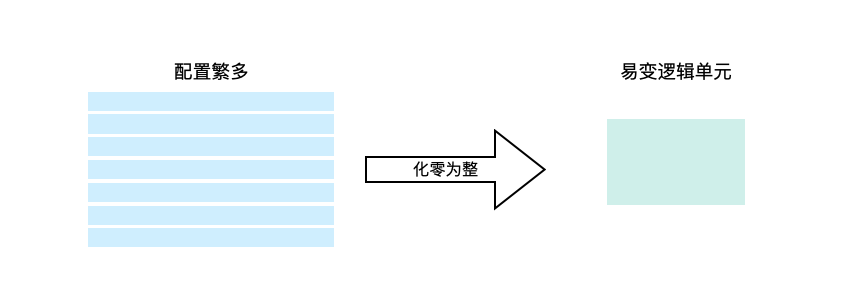
这时候不如直接用整块代码的“规则引擎”解决问题,一块代码完成整体的决策,每次改动时还可以兼顾到整体的决策逻辑。
4.2 关于变化的收敛
我们在进行代码编写时,如果想让代码稳定可维护(架构的可扩展性、灵活度方面),最重要的就是通过各类变化的收敛,让影响范围可控,让整个的架构变得清晰,让整个代码结构变得清晰。
而变化可以大致分为这么几类:功能繁多&耦合过重导致牵一发动全身、易变的串联关系、易变的组合关系、易变的单元逻辑、新增的单元逻辑。
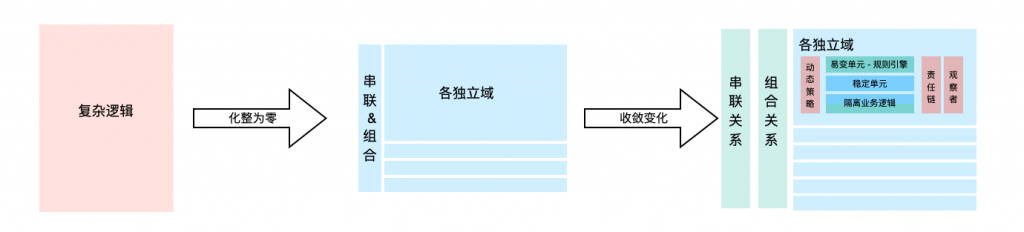
导致我们修改代码的都是业务功能上的变化,可以从业务功能上进行探索,最佳的实践是:“化整为零,分而治之”,对于易变单元 “切分易变逻辑,使用中间件收敛和控制变化”,具体来看
- 对于
功能繁多&耦合过重导致牵一发动全身,我们可以在最上层做处理,拆分独立的服务(比如按照领域拆分),将各域的变化收敛到域内,不影响整体系统的变更。 - 对于
易变的串联关系,可以借鉴观察者模式,实现发布订阅等能力,完成整体的逻辑串联(落地形式可以是 基于总线的同步触发机制、又或者基于消息的异步触发机制),而不是硬编码来完成逻辑的串联。 - 对于
易变的组合关系,可以采用本文所说的这种模式,快速拼接现有的功能组成对外服务,而不是次次硬编码。 - 对于
新增单元逻辑,我们可以使用策略模式,完成单元逻辑的收敛,把新增的成本给解决掉。 - 对于
易变的单元逻辑,通常是由于业务逻辑多变引发的,最佳的就是拆分业务决策逻辑、代码决策逻辑,然后把代码抽象为执行模版,复杂的业务计算交给规则引擎。比如金额计算、过滤规则等等,还比如策略模式中的计算策略。
之前描述的,事件总线-流程编排、交互总线、规则引擎、通用奖励服务、代币账务等,都是按照这个思路实践的,有兴趣可以看下。
4.3 创新的吞吐量 – 题外话
说句题外话,从流程上来看,从idea提出到完整性够键、再到prd产出、研发开发、测试、线上运行,这几个阶段是否可并性,常规来说是不可行的,prd未产出细节可能会出现大量的变动,导致研发返工,研发阶段测试提前介入,会导致测试工作重复等。但是在成本极小的情况,这种模式是有落地可能性的,尤其是创新场景,直接研发写个demo上去也不是不行。
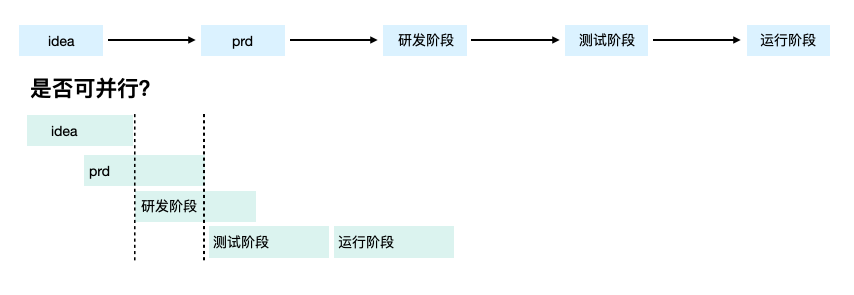
一定程度的并发,虽然整体工作量稍微增加,但是因为排期变短,整体的吞吐量是上升了的。
4.4 性能的优化
整个落地过程碰到了许多问题,允许我感慨下,代码都是人写的,所有的软件层面的引发的性能问题,都是可解的,只不过选择性能时我们需要牺牲一些东西,比如Groovy的动态性、比如空间换时间等等。
考量性能最关键的指标就是,有效吞吐量、响应时间,基于这两个做综合判断,往往能达到性能优化的最佳状态。
不要一堆问题混起来考量,分成单元问题逐个击破,就简单很多了。
有兴趣可以读一下架构视角的性能优化
4.5 易用性和灵活性
每次做中间件或者工具设计时都会发现,易用性和灵活性天然是冲突的,易用和简单基本可以划等号,但是简单基本意味着变化可能性小,灵活性好不了。
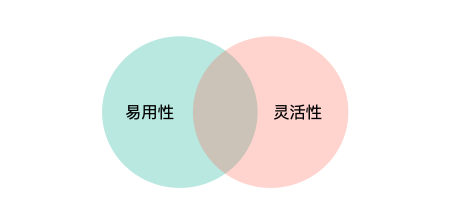
需要注意的是,易用性提升前期,比如新增一个功能能够让整体更好用,同灵活性并没有什么冲突。
4.6 架构的广度和深度
日常扩大技术广度,使用时提升技术深度,是最佳的实践啦,有足够的技术视野才能做出优秀的架构,有足够的技术深度还能保证架构的有效落地。
5. 写在最后
本文描述了创新试错下的多变开发模式,我们可以通过何种方式,提升面对变化时的效率,并对于理想的方式进行了技术实践上的落地,并且切实解决该场景下的问题。
其中技术实现,是以主流开发语言Java 作为基准的,如果你们是其他技术栈,可能实现细节不同,但是整体的思路肯定是相近的。
对于这个思路都是类似的实践模式,相信做过Faas或者Serverless的朋友都有相同的感触吧,能根据场景,把思路落地才是关键。
最后从整体的思考、设计、落地过程中总结了一点经验,也分享给了大家,如果有更好的思路,可以一起探讨。
新的思路、新的技术总能带来一些较多的收益,带也会带来一些麻烦,完整考虑收益,因地制宜才好。