0.前言
本文要讲的是,如何让架构设计/优化中的行为变的有迹可循,如何更系统的去解决问题,让经验变为普适类的方法。而不是面对一系列的结果数据抓瞎,依赖少量的经验进行盲猜。
本文以技术架构优化、业务打法优化等多个视角来看基于热力分布的问题优化,基于数据沉淀,去完成问题发现、问题热力分布分析、问题的高ROI解决。从优化的角度出发,先定义问题,再定义问题的影响模型,再看整个模型对于不同场景下的应用,及一定的实践思路。
整体举例以营销活动、技术架构场景为例,讲述当前红海竞争中,我们应该如何科学的去做活动业务、去做系统优化。
1.定义问题
我们做架构设计、架构优化的初衷是围绕整体目标,规避问题、弱化问题。而这些所有的前提是我们要知道目标是什么,阻碍目标达成的是哪些事儿,而这些事儿就是所谓的“问题”。
无论是技术架构、产品架构、业务打法,又或者是组织架构,均是如此。
1.1什么是问题
首先明确什么是问题,这样才能更好的对问题进行寻根究底,对问题的进行优先级排序。
那什么是问题?
通常来说,以我们的系统/行为为观察对象,问题的出现会有两个表现形式:结果类事实、原因类事实。
| 结果类 | 原因类 |
|---|---|
| 系统平响差、有效吞吐过低 | 系统内慢SQL较多 |
| 活动效果差 | 活动内任务玩法转化效率较低 |
| 系统存在较多的丢单 | 系统无事务等数据一致性保障措施 |
我们需要的是一个完整的问题,不能仅仅是结果或者原因,而是以结果为切入点,探究结果类问题背后的原因类事实。所以如果下一个定义:
导致“劣化的结果”的缺陷行为,定义为问题。

1.2 结果类描述
如果判定一个事儿有问题,首先是从结果出发的,最简单的描述就是“不达预期”,甚至产生恶劣影响。
对于这个事儿的描述通常是围绕目标的各项指标展开的,对于结果类描述应该是:指标+差距/负向程度
比如说:
qps 承载量低于预期承载量500qps
拉新数量低于目标值1.5w,仅达成50%,并发生资损活动预算存在80%被刷走,无法投入正常活动运营。
丢单数量日均200单,预期为0丢单。
1.3 原因类描述
原因类的描述对象通常是“行为”:什么不好的问题发生了、整个系统存在一些不健康的缺陷行为、我们的某些执行存在偏差。
原因类问题,通常相对细节;结果类问题,通常过于笼统,但两者缺一不可。
ps: 刚工作或者容易陷入细节的同学,呈现的大多是原因类描述,而老板们关注更多的是结果描述,如果恰好你是一个架构的设计/实施者,你绝对两方面都需要,因为只有齐备的情况下,我们才能展开问题的解决工作(架构设计/优化)
2.问题的影响模型
一个事情对我们呈现的问题是杂乱无序的,我们没办法直接判断到底哪个问题是最紧急、最核心的;也无法判断到底是哪些缺陷行为导致了不达预期。我们需要对于这一系列的问题进行影响力建模、问题的分布建模,让我们的对于问题的解决有迹可循。
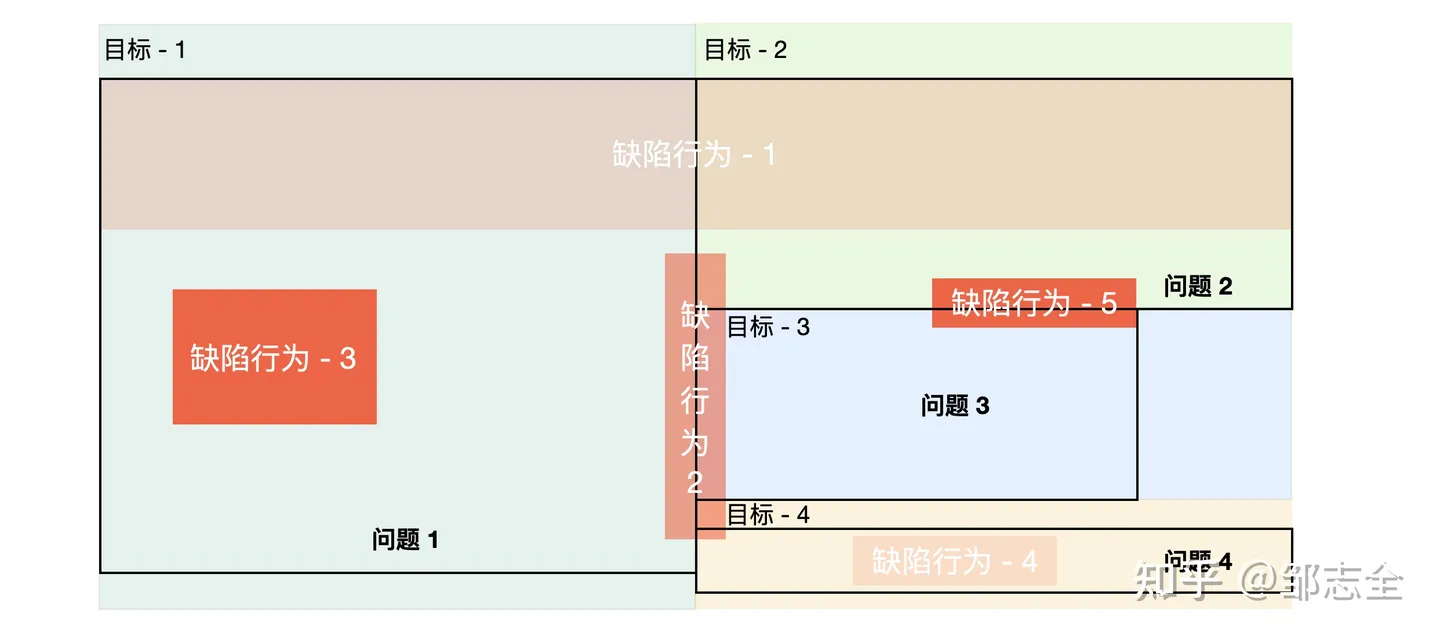
2.1 热点问题挖掘 – 问题影响力及分布
首先是问题的影响力,我们需要对于问题进行影响力的评估。一个问题到底严不严重是受很多因素影响的。
简单来看一个问题的影响力的重要组成因素,围绕我们的目标出发,主要有:目标的重要程度、受影响目标的劣化程度、缺陷行为发生的频次,而影响到我们目标的通常不是一个行为,而是由多个缺陷行为共同构成的劣化结果,每个缺陷行为可能会造成多个指标不及预期,我们需要把每个问题的生命周期和具体分布引入进来。
我们适当的对于这几个影响因素进行组织:
问题影响力 = 对目标的结果影响力 = 目标重要程度 * 目标劣化程度
缺陷行为影响力 = 影响时长 * (对目标1的结果类影响力 * 导致的劣化程度 * 发生频次 + 对目标2的直接影响力 * 导致的劣化程度 * 发生频次 + ...)
怎么把缺陷行为同目标结果尽心关联呢?又如何进行热力呈现呢?
最直观的就是以“运行视图”的视角进行表达,在运行时图中我们可以清楚的拆分出每个具体的行为,每个链路对于结果的影响。(可能是多个链路共同构成功能,功能目的表达为结果)

比如说:
- 系统的调用链路
- 系统的数据流视图
- 用户使用系统的信息流视图
- 业务的资金流视图
- …
我们可以因地制宜,结合架构的多视图、业务打法的多视图,进行整体脉络的元信息表达,在整体的表达过程中,建立Trace机制,把具体的运行数据给埋入&串联,结合这一系列的数据,进行上面公式的计算,最终完成建立在运行视图之上的热力呈现
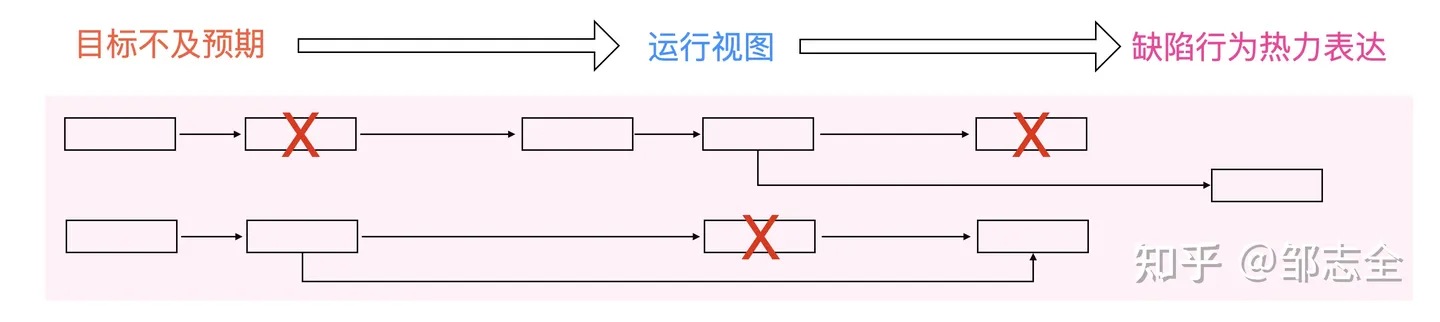
2.1.1 热力的计算
我们的目标是解决问题,优化指标。但是具体的实施过程的是针对一个个缺陷行为去操作的;并且对于问题的我们是有容忍程度的。
这就意味着,具体的解决过程,我们不能按照目标的优先级进行排序,不能依次解决问题域内的每个缺陷行为;也不能根据影响目标的数量进行排序,忽略其对目标的影响程度和目标自身的重要程度。
一种最佳的方式,进行影响力的热力分布,进行缺陷行为计算后影响力的排序,依次最显著的缺陷行为。更好的全盘的角度去看问题,某个行为的优化是不是解决了所有的问题、会不会引入新的其他方面的问题。
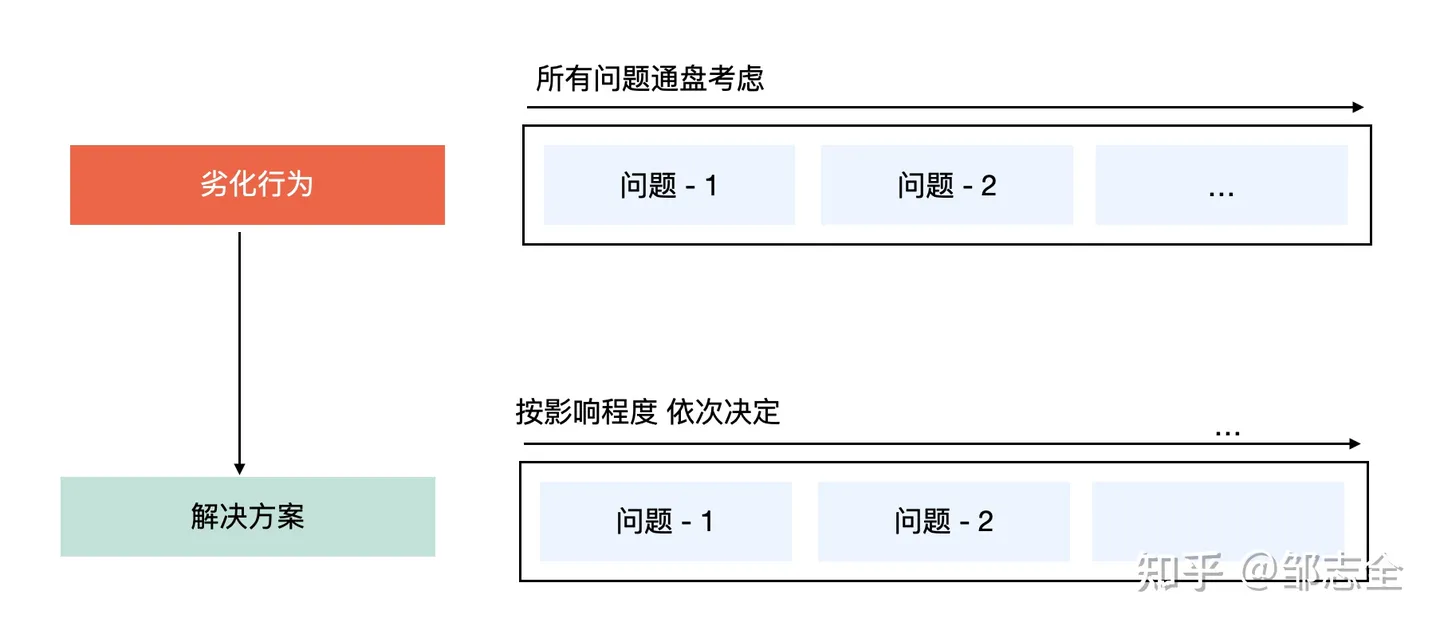
如果问题域间存在互斥,比如说解决一个缺陷行为,某个问题被大幅度改善,但是其他问题依旧,或存在劣化的情况,如果没有更好的替代方案,就按照优先级依次解决。
ps:很多时候做设计时,往往会面临取舍,不妨试试以上方式,看看到底优先要哪个目标。
2.1.2 缺陷行为导致结果098的劣化程度
上面**“导致的劣化程度”**这个因素,是相对模糊的,这个值的误差会一定程度上影响我们决策。
很多场景下并非简单的组合关系,我们可以清楚的拆分出A占30%、B占60%、C占10%,我们需要对于我们的链路和场景进行具体的分析。
这里有几种关系:
- 0-1关系,只要存在就一定有问题,每个组成部分都起决策作用
- 组合关系,比如耗时、平响等等,我们可以相对轻松拆分出每个劣化行为占比有多少
- 短板关系,以组合关系中最差的影响作为判定标准。
- 分支递进关系,一层层漏斗,第一层漏斗占比会更高,漏斗层次越深,本质上带来的影响越低,是一个衰减的曲线
更多的需要具体情况具体分析,根据场景构建模,判断分析就好。
2.1.3 关注成本
问题的解决是需要成本的,上面完全是建立在成本均可接受的基础上的,但是现实落地过程,成本是不可忽略的,我们需要把成本因素加到排序过程中去,来计算对应的ROI。

对于优化而言,把成本加入去是合适的,但是对于“故障”类问题,成本因素基本是可以忽略的,因为不解决带来的是毁灭性代价,而非失去提升。
2.2 劣化趋势
正常来说,无论是设计、还是优化架构,我们关注的都是头部的大影响力问题、头部的缺陷行为,但是尾部的问题也是有很大价值的。
这些问题本质上就是我们的“债务”,需要时刻谨防长尾小问题的膨胀、放大,尤其是相关的发展趋势。解决小问题的优先级可能没那么高,但是杜绝小问题转化为大问题很重要。
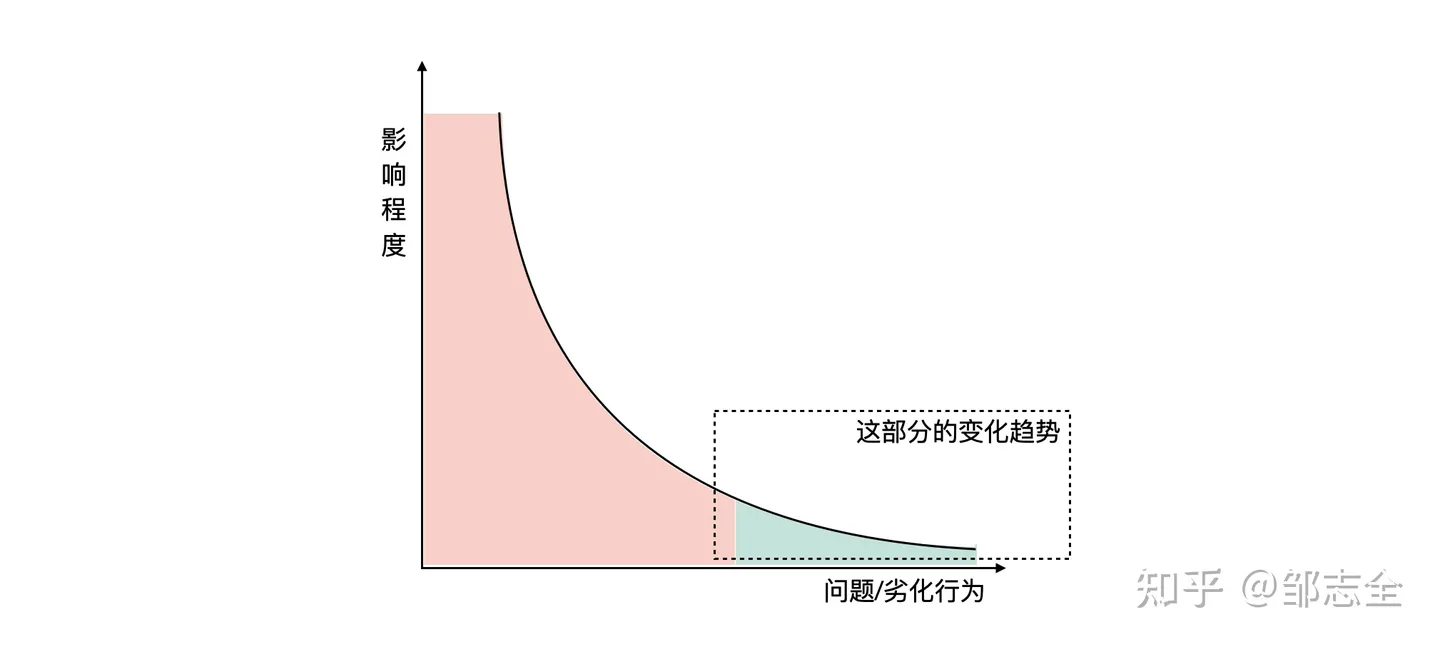
2.2.1 极端/异常分位数 – 定时炸弹
对于趋势而言,去判断“缺陷行为的影响力”是否会忽然放大、是否存在“持续劣化”的可能。一个简单的方法是观察这个行为的极端/异常分位数,这些值代表了最坏的程度,因为发生的极少、存在的时间跨度较小,导致问题并不凸显。
对于极端/异常,但出现时间较短、频次较小的缺陷行为,也需要我们去高度关注,尤其看是否有劣化的趋势。
在航空领域有一个法则叫做海恩法则,一次严重事故的发生之前,都会有29次轻微事故、300次先兆、1000次事故。关注长尾中潜在的问题是挖掘事故、排除事故、预防事故最佳的实践方式。
2.2.2 易容忍的行为 – 温水煮青蛙
那些频率极高,但影响程度甚微的行为,才是我们可以大致容忍、甚至忽略的缺陷行为,唯一需要注意的就是别积少成多,屎山往往就是这么来的,我们需要关注的就是这类缺陷行为的数量,把它们控制到一定的量级之下即可。
3.各方面的落地探索
我们尝试以活动业务落地、技术架构等两个不同的角度进行分析,看整个体系可以给我们带来什么,如何因地制宜去帮助我们解决实际的问题。
3.1 以营销活动落地举例
营销活动中最核心的是:生产效率、资金效率,资金效率又可拆分为流量成本效率、权益成本效率,活动的落地,均是在此之上,去构建拉新、拉活、品牌营销、促转化、提GMV等若干目标的。接下来就看下怎么落地问题的热力视图辅助业务高效率落地,如何提升资金效率,用10w预算做出100w的效果。
3.1.1 流量成本效率
先来看流量效率的优化。
就拿最常见的 签到 + 任务 + 领奖 + 拉人红包的活动来看:
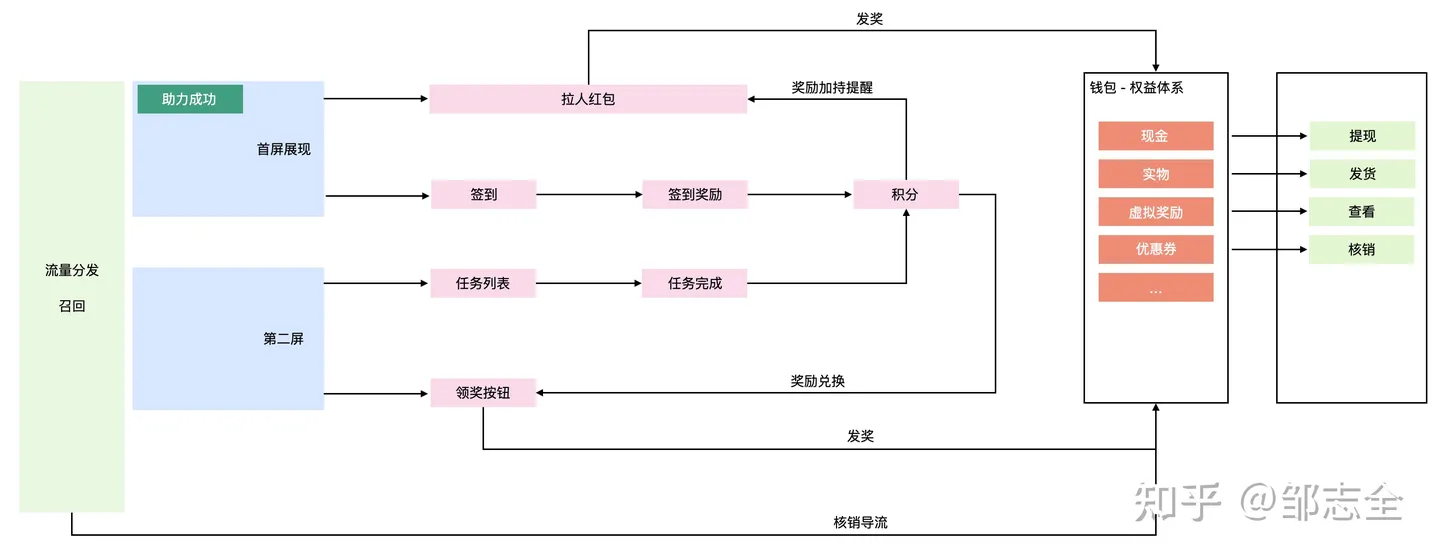
第一步,我们围绕目标进行建模,核心的目标是什么:拉新 + 留存、促活
第二步,对于用户参与活动的路径进行梳理,拆出每一个关键的的用户行为、用户的入口。
第三步,建立路径同目标中的关系,预期转化占比。
第四步,每个关键路径记录用户行为数据,打通前后端数据,建立业务Trace体系。
第五步,分析活动内部热力情况,检查每个群体下的热力情况。
第六步,进行对应的规则、内容调整。
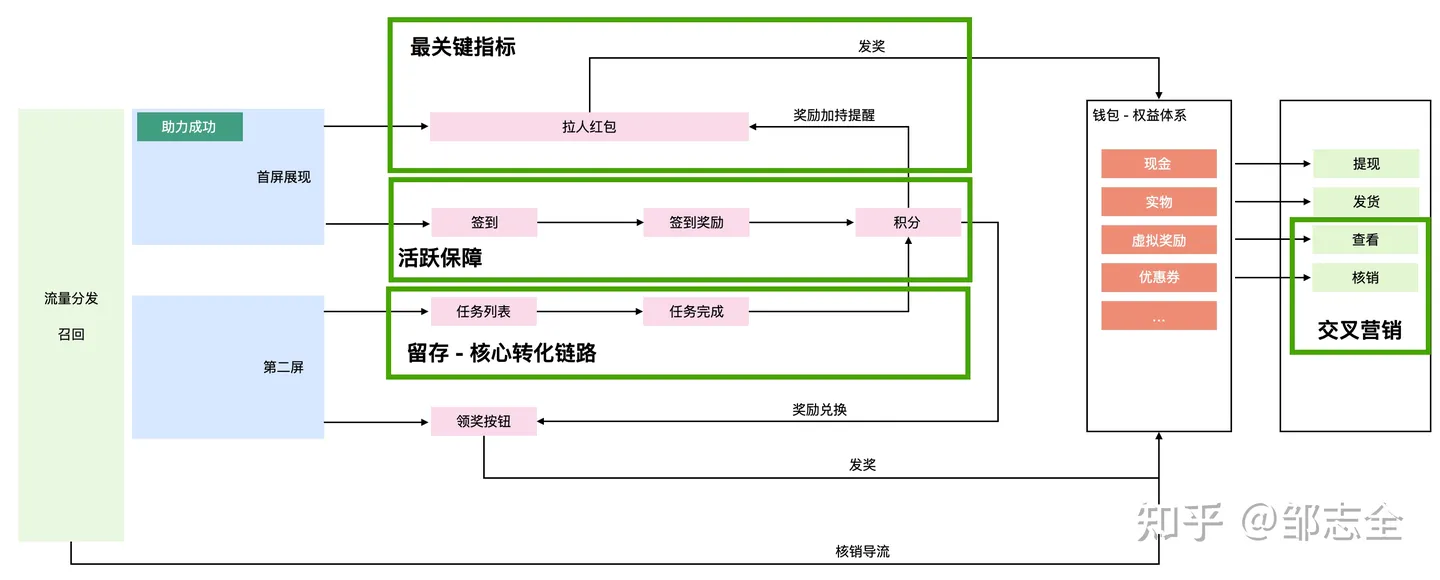
3.1.1.1 流量转化漏斗分析
对于上面的活动进行剖析,指标往往是难以达成的,链路太长干预措施太少,而通过上面的分析体系,可以让我们清楚的看到用户停在了哪一步。
每一步都是坑、每一步都是漏斗,尝试分析后我们会得到若干带有用户特征的已经排好序的缺陷行为:
- 用户进入活动,秒关
- 划了划页面,关掉
- 点了下签到,关掉
- 点了下任务,关掉
- 点了下分享,再未进入活动
- 获得积分后,完全不用
- 拉人成功后,不领红包
- 活动仅参与1次
- 活动参与2-3次
- 深度参与活动后不核销权益
并且通过活动热力图,我们可以清晰的看到,有多少用户止步在了哪一个环节。
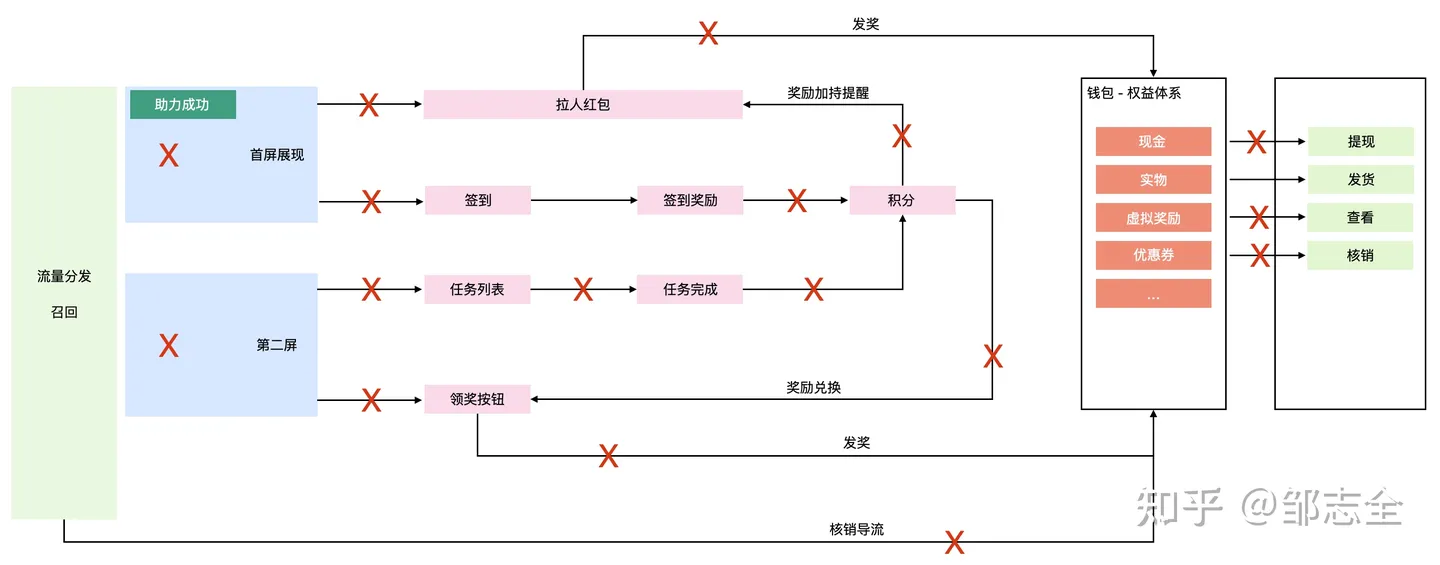
3.1.1.2 流量转化漏斗优化
具备上述的能力之后我们就可以针对活动进行针对性的打击:
- 用户进入活动,秒关 – 增加天降红包引导,第一笔立即提现
- 划了划页面,关掉 – 稍弱于天降红包的活动指引
- 点了下签到,关掉 – 签到后,告知用户获得拉人加持红包 促传播
- 点了下分享,再未进入活动 – 合并签到 & 拉人功能,增加玩法引导
- 点了下任务,关掉 – 这可能是个好事儿,被转化了,如果仍有传播目标,可适当召回
- 获得积分后,完全不用 – 增加玩法引导、以积分为介质增加召回能力
- 拉人成功后,不领红包 – 增加强召回措施
- 活动仅参与1次 – 可能是找不到活动入口
- 活动参与2-3次 – 可能是召回力度不够
- 深度参与活动后不核销权益 – 活动即将结束时统一召回
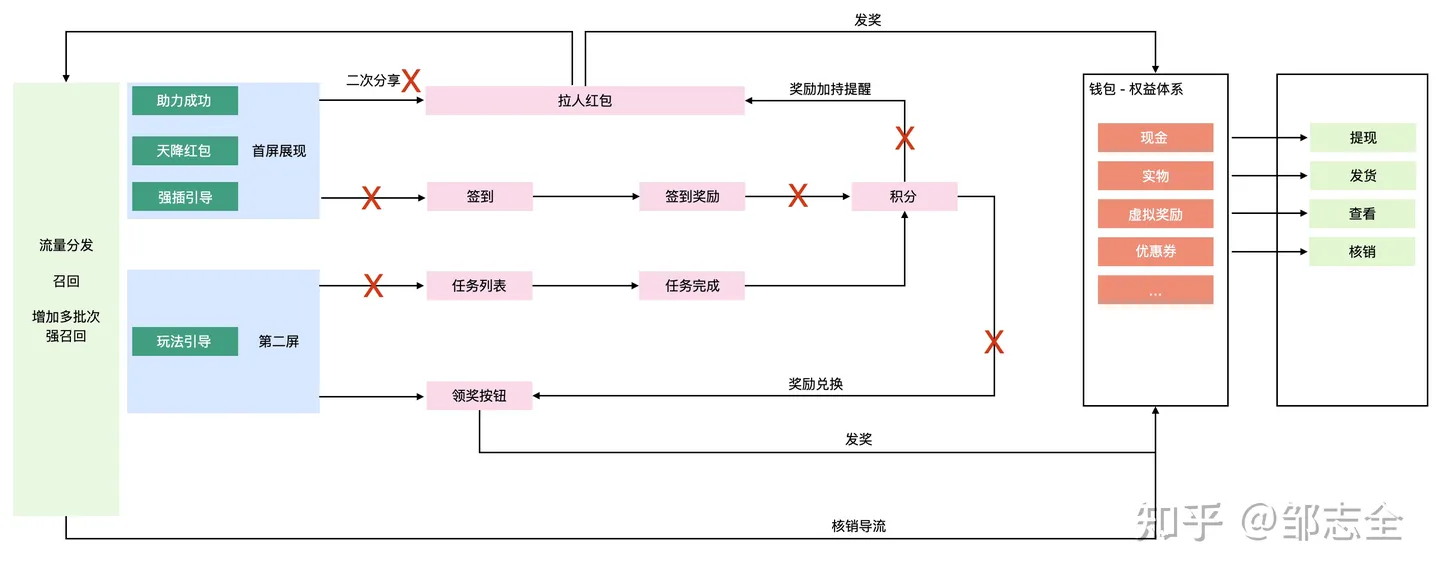
增加如上措施后,发现解决了大部分缺陷行为,整体的活动效果数据有了很大的改善。
但是仍有部分漏斗转化效率过低,尝试分析,仍然能拉出较多的链路,看整体的链路应该是和积分有很大关系,活动中的链路过长、概念过多,增加了用户精力的消耗成本,不妨试试换个玩法。
核心玩法简化后,直接去除积分概念,以现金作为强引导,并在签到上增加了现金翻倍的直接提示,任务完成随记翻倍、随记发放其他权益。
并增加页面/APP停留计时红包策略,引导用户常驻。
我们还可以增加更多的分析策略,比如第n次的意愿,分享行为发生在第几次,用户连续签到多少次后有意愿尝试其他玩法等等。
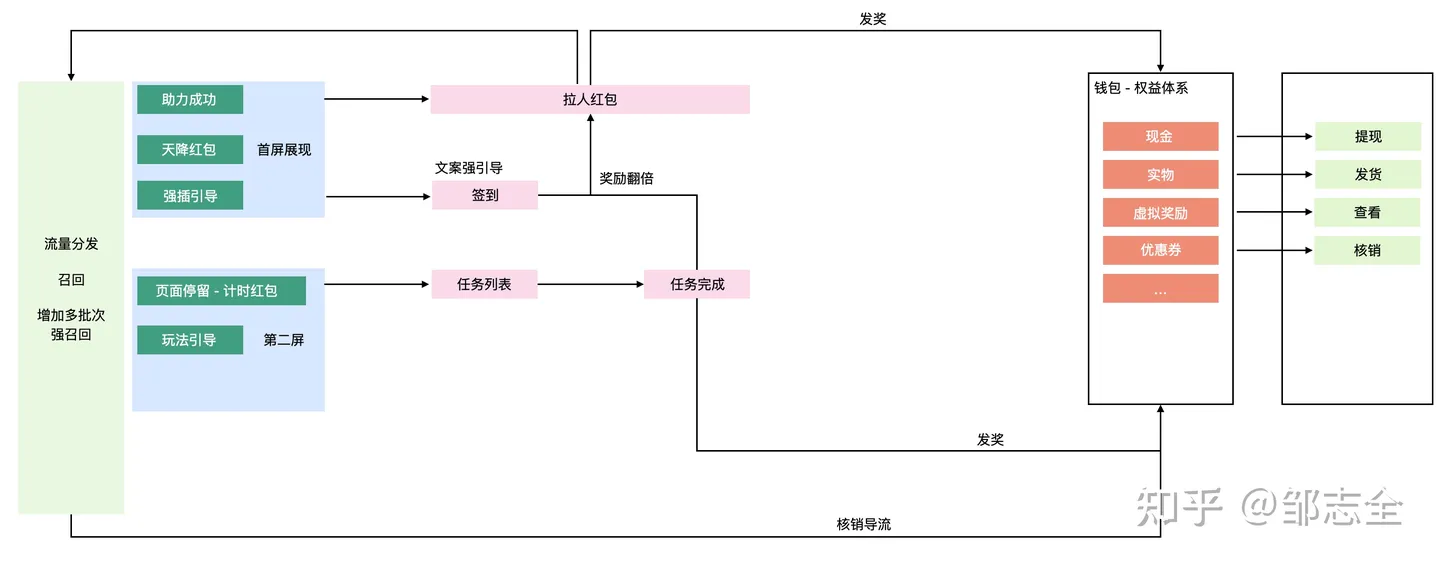
3.1.2 权益成本效率
上面提到的玩法,权益都是整个活动周期内的,如果围绕权益进行分析不难发现,90%的资金都在空转:用户参与活动 – 权益发放 – 权益过期
同样的我们仍然可以利用上面的方法对于活动规则进行分析,这里的缺陷行为,相对转化漏斗的定义要难一些,我们需要定义资金流视图,而非用户参与的信息流/操作流视图。
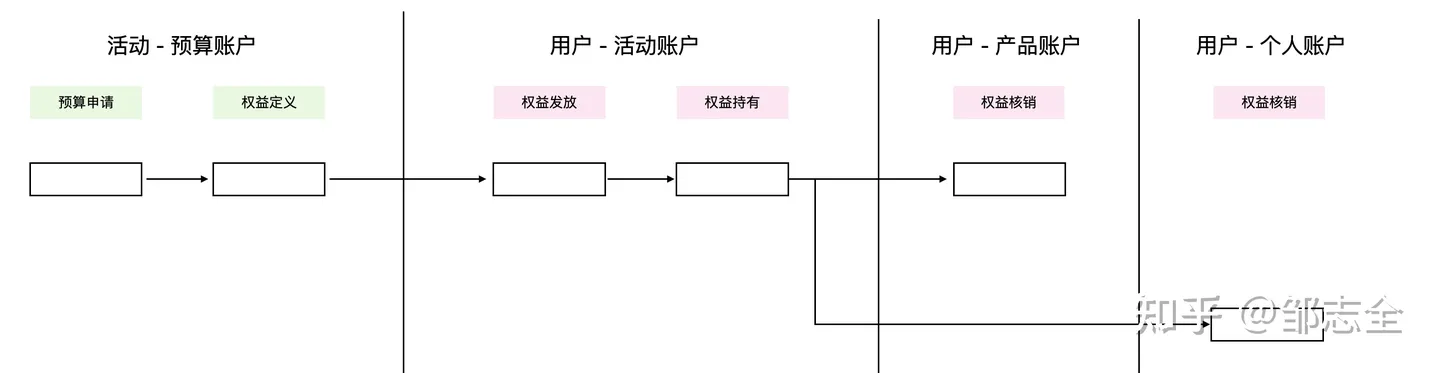
在梳理出对应的运行时图之后,我们就可以对于行为进行定义了,定义好行为之后,同样可以按照上述的方式进行问题的热力分布分析。
分析之后不难发现,大致可以归为以下几类问题,但是每个活动问题虽然类别相同,但是具体的问题表现是不同的:
- 权益表达类问题:免费权益不要、5元成本的优惠券用户不感冒、1元红包欣喜若狂
- 权益空转类问题:预发式权益用户无感知、用户获得权益后不核销
- 权益价值类问题:有的人0.5元也会日日参加,有的人给他10块也不要
- 转化类权益较少:单一全用现金,权益起到的转化效果减少
当拿到活动资金热力图之后,我们基本就获得了哪些权益有效/无效、多少权益在空转、多少权益在被浪费、权益带来的转化效果是否过低。
接下来分享一下,关于权益设计,也就是活动资金优化的一些技巧。
ps:资金流视图是支付资金链路优化常用的一种工具
3.1.2.1 资金效率优化 – 权益表达类问题 & 权益价值类问题
资金价值 不等于 权益价值,多尝试用户感冒的权益会有效的多,一定不能吃大锅饭,可以试试单用户群体集中攻破

3.1.2.2 资金效率优化 – 权益空转类问题
减少活动资金占用,10w花出100w的效果
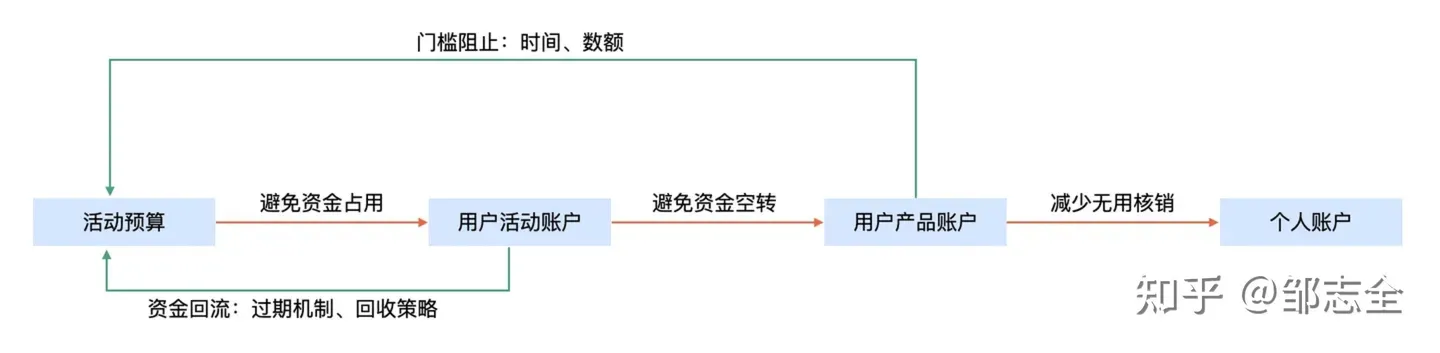
3.1.2.3 资金效率优化 – 转化类权益较少
合理分布活动权益,绿豆中撒红豆,将现金分散到整体的权益体系中,使用现金拉用户,使用权益促转化。
3.1.2.4 跟做推荐一样,一定要考虑兴趣随时间衰减
把时间作为计算的其中一个因子,带入时间衰减系数,不断调整用于适应用户的敏感程度。
3.1.4 AB TEST
上面说的所有的数据都是需要数据积累然后进行实验对照的,单纯切换规则做测试,虽然能解决大部分问题,但没控制唯一变量不说,对于问题的解决效率是比较低的,我们应该充分的利用时间和空间来进行规则的调整实验。
- 活动上线时,就以多套规则上线,切流为多个活动,测试具体运营行为的有效性。
- 多人群测试,查看不同人群下对于本次活动的感冒程度。
- 前20%流量快速跑通MVP,后80%流量博取大头收益。
- 活动间相互赋能,多个其他活动中沉淀的经验结果,基本可以代表本次活动中该玩法的表现。
- 除针对自身产品的APP画像外,尽可能建立针对活动的画像。
3.1.5 活动分布优化
不仅是活动自身的行为规则的调整,很多时候营销活动是多个活动构成了一盘大棋,每个活动并不是独立存在的,而是互相配合进行整体产品目标辅助落地的,一个个孤立的活动只会让整体的效果越做越差。
比如专注于拉新,留存适当放空一下,留存交给后继的活动去做,可能效果反而会更好。
对于整体的目标,活动就变成了一个个具体的行为。前面提到的分析方法也是可行的,定制化落地即可。
3.1.6 生产效率优化
生产效率本质上是活动的交付效率,我们可以按照迭代效率的思路进行优化,营销活动系统的最大的痛点在于变化,优化最核心的手段就是封装变化,如果不确定热在哪里,可以利用本文所说的方案看看到底热在哪,用技术手段去解决这些热点问题。
具体可以参照我之前的,《营销活动提效之道》 来看下如何落地的。这里不过多赘述,主要描述本文所说的问题的洞察体系如何赋能活动业务的落地,举一反三,看如何赋能其他的业务。
3.2 以技术架构举例
首先进行整体指标的建模
单就系统的技术指标而言,通常有“性能指标 – 平响时间/有效吞吐极限”、“数据一致性 – 丢单/错单率”、“扩展性 – 系统迭代成本/效率” 等指标,这几个指标也大致能描述我们一个系统、一个技术架构的健康程度。先来看一下整的概貌:
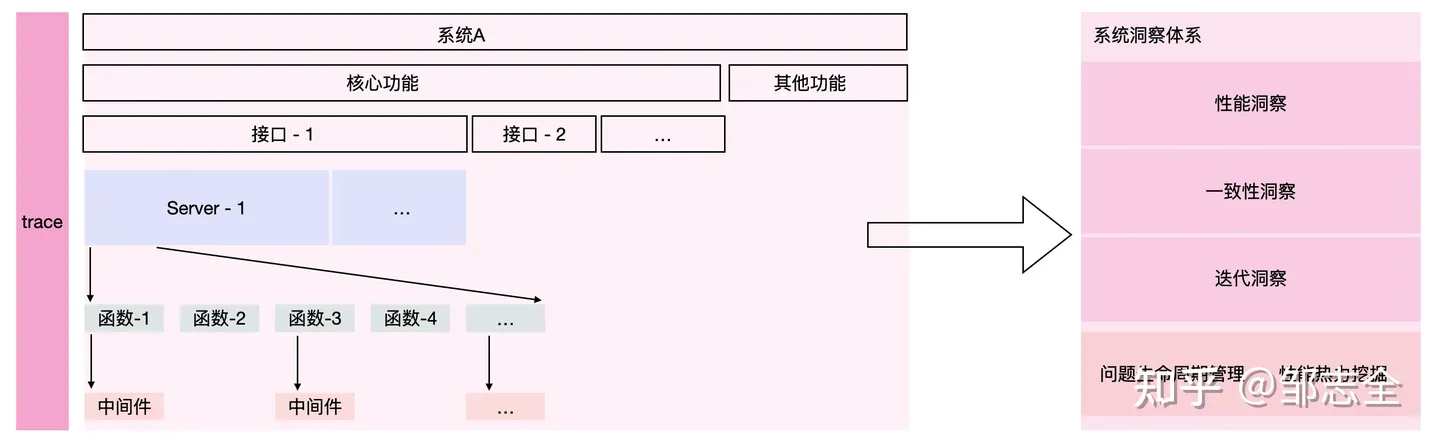
3.2.1 线索的建立
首先对于行为进行串联,系统的核心指标有哪些,核心指标涉及哪些功能,功能由哪些接口构成,接口中涉及哪些服务的调用,涉及每个服务中的哪些函数、哪些数据、哪些中间件使用。本质上就是一个系统的运行视图:调用链路、数据流图。
前半部分信息属于元数据部分;后半部分依赖于Trace机制的建立,要有一个Trace能跟踪到一整个的执行路径。
ps:目前业界的Trace机制实现都相对成熟了,可以关键词搜:Trace系统建立
3.2.2 行为的埋点
具备Trace之后我们需要对于动作进行埋点,需要关注的主要是:新系统建议全链路埋点、存量系统入口处埋点、存量系统变更处埋点、数据节点同步携带trace索引。
可以通过切面的方式,指定函数进行切入。埋点时机不怕多,但是一定要加埋点开关,埋点也是有代价的。可以根据自身的场景进行全量埋入、仅计数、rate后埋入、条件埋入、稳定时关闭等等。
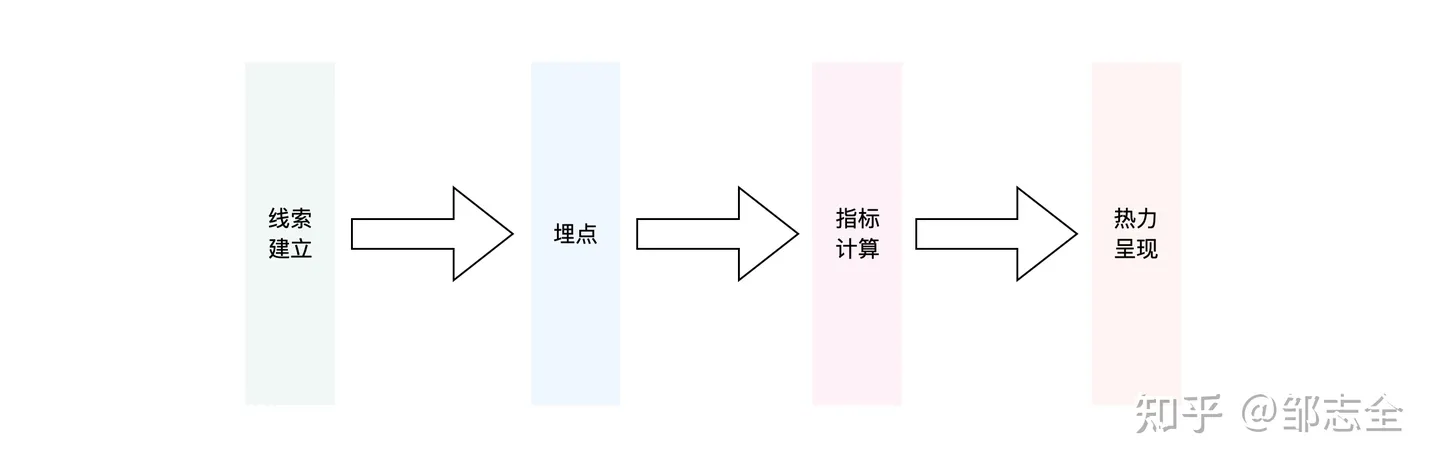
3.2.3 性能观测
数据埋入后,我们就可以对于整体的数据链路进行问题了,按照前面提到的方法:
问题影响力 = 对目标的结果影响力 = 目标重要程度 * 目标劣化程度
缺陷行为影响力 = 影响时长 * (对目标1的结果类影响力 * 导致的劣化程度 * 发生频次 + 对目标2的直接影响力 * 导致的劣化程度 * 发生频次 + ...)
第一步:对于系统功能、功能内接口进行重要程度分级、设置对应的合格、优秀等评分指标。
第二步:拉取核心链路中的具体行为(系统#功能#接口#服务#函数/三方调用 标识一个单元行为),对于行为进行健康度评定设置,筛选缺陷行为,初始化可按照默认最严标准进行设定。
第三步:由于性能方面通常是组合关系、短板关系,影响程度就是主要是各个组成部分的占比关系。
第四步:持续运行后,进行性能问题热力分布呈现。
至此我们就获得了问题的影响力排序、缺陷行为影响力排序,及整体的问题热力分布情况。
3.2.3.1 以耗时为例
问题影响力排名第一:
核心系统中系统A 功能1的/cc接口超过预期耗时800ms,原因是接口中的2次SQL调用超过400ms,两次Redis调用超过100ms,下游调用超过200ms
缺陷行为影响力排名第一:
数据源abTest的单词调用超过200ms,导致问题1、2、3,影响到功能1、2、3,影响占比分别为1:60%、2:30%、3:10%
性能问题热力分布为:
XXXXXXXXXX
3.2.3.2 以吞吐量为例
开启profile采集后压测收集:
核心系统中系统A 功能1的/cc 接口极限qps承载量为50qps,低于500qps预期,原因是接口中的2次SQL调用超过400ms,20次XXX函数执行CPU占用过高
3.2.4 数据一致性观测
主动性埋入:我们可以针对系统内的关键数据节点进行Trace埋入,通过主动上报、binlog核对、或异步扫描对账的方式定时发现不一致情况,并进行异常数据节点的记录。定时发现每个功能中存在哪些数据不一致情况发生,记录具体的缺陷行为及受影响的功能。
被动记录:我们可以记录每个功能被“客诉”的“错单”/“丢单”case。
根据对应的结果数据、缺陷行为等数据构建具体的问题的热力分布,按照诉求提升对应的DB的可用性、补全事务机制、增加补单机制等。
3.2.5 迭代效率
每次交付流程中,记录涉及每个代码文件的变更次数、变更行数、交付时间跨度、故障发生记录、bug发生记录等,监控每个功能的维护背后的变更成本。
如果一次交付超预期工期可以定义为问题点;如果一个文件的变更次数/bug数/故障数 超预期则标记为缺陷行为。
依次构建整体系统的迭代效率指标,超标时,该重构重构。
4.洞察体系的落地基础
要落地整个体系,我们需要做哪些事儿,简单来说就是一个埋点 + 分析的系统,对于小数据规模、海量数据规模实践思路是不同的。
4.1 洞察体系的建立
前面提到我们把 **导致“劣化的结果”的缺陷行为,定义为问题。**要想定位和分析问题,首先我们要对做的事儿有一个详细的呈现(系统状态、业务状态等等)
第一步,要有对于结果数据的记录,这一步通常大家都会做。
第二步,我们要围绕整个运作链路,有导致这个结果的具体的行为数据。比如 我们至少要知道整个的**“运行视图(有哪些行为、如何运作的)”**,每个行为所处的环节、行为的存在周期、具体行为的指标、行为发生的频次。
第三步,我们对于这些数据进行洞察指标的建立,定义出哪些结果不达预期、哪些行为属于缺陷行为、行为和结果间的因果关系
第四步,围绕目标,对 问题、缺陷行为 进行分布呈现和热力处理。
最核心的是2、3步,目前业界常常缺失就是这两步,致使对于分析过程完全经验之谈的“猜测”、“推测”。
4.2 背后的技术支撑
数据量的大小,对落地实践影响很大。
小数据体量 记录/分析简单,但样本过少,结论置信度不高;
海量数据 只要分析方法正确,结论一定是确信的,但是落地的成本和代价比较高,记录和分析难度都相对较高。
4.2.1 什么是好的
由于我们通常会面向这个分析体系进行对应的优化决策,一个好的分析体系,有这么几个诉求:极为准确、近实时、低成本、易用性高

围绕这部分数据,甚至我们会启动自动化的动作优化决策和执行。
4.2.2 小数据体量实践
对于小数据体量,比如说组织结构效率的分析、运营动作的管理分析,就是一个简单的数据记录 + 报表系统。
最常用的实践是对于我们操作的平台增加一系列的埋点动作,我们能记录每个人、每个事件的发生周期,比如让整个交付流程清晰可见即可。并且数据量越小,问题发现/分析的难度是越高的,更多的还需要人为的数据注入。
个人观点哈,体量较小时,一个优秀的领导者、PMO、架构师 往往比做数据分析要来的更具性价比。
4.2.2 海量数据实践
海量数据难点主要是对于数据的实时埋点、海量数据存储、线索的处理、数据的小成本呈现。
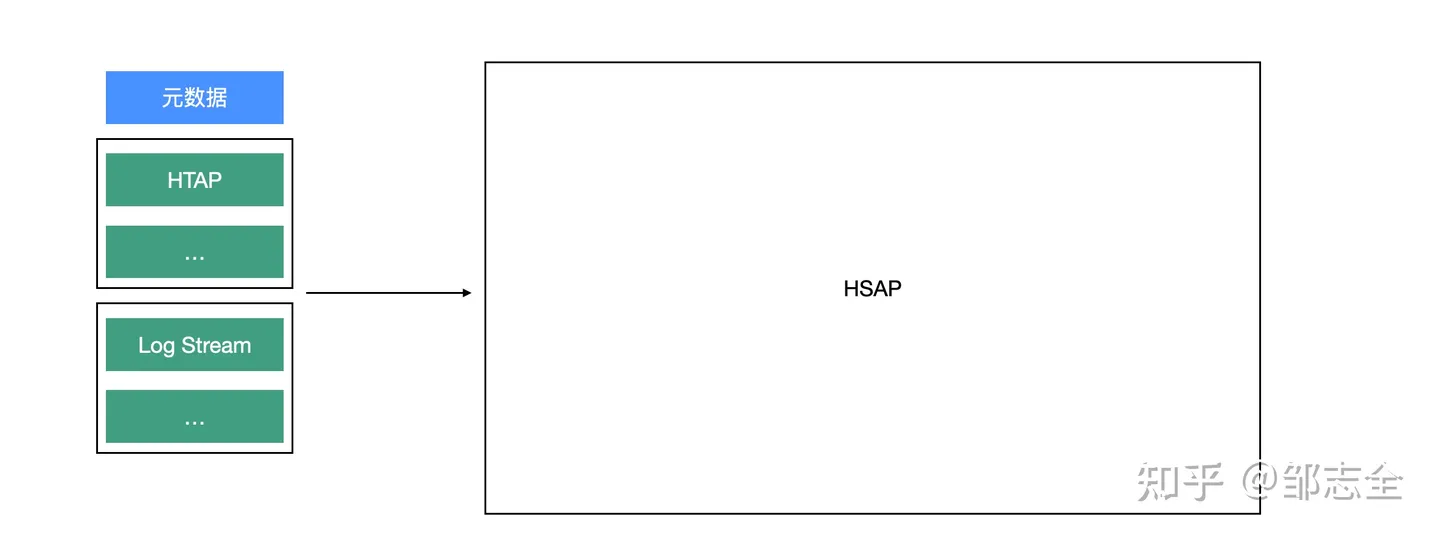
本质上就是一个这两年比较火的HSAP系统(Hybrid Serving/Analytical Processing)的落地,传统的OLAP系统并不能满足我们的诉求(近实时体系下的写入、高负载查询能力、伴随不同场景下的弹性伸缩能力、隐藏多引擎的实现细节)
具体的实践相对复杂,这里先提供一个搜索词,后面会替换为对应的《具体架构设计实践(以营销活动下的效果洞察及反哺能力)》的链接,本篇要聊的是,如果基于这样的体系进行问题发现、问题热力分布分析、问题的高ROI解决等方法哈。
5.写在最后
正如前面提到的,对于架构/打法的优化都是围绕目标,结合整体结构&路径进行“缺陷行为”热力分析,依次迭代最终让架构/打法走向健康。
这是一种相对科学的实践思路,但通常是在有一个雏形之后的实践思路。一些相关工作的启动,还是在各种科学方法论之下,辅以经验去构建最初的那个雏形。
确定雏形、不断优化、达到健康状态、防止劣化、不断优化 基本是所有架构的发展过程,前面说的方案本质上是在帮助我们避开让问题变的只有“重构”才能解决。但如果架构、打法面临的场景、业务发生了巨大的变化,又或者组织结构发生了重大的变化,通常意味着心的架构/打法,越及时重构,收益越明显。
本篇侧重的都是方法和思路,具体的实践细节,可以关注后续的更新。有描述不对的地方,恳请斧正,有更好的思路,或者已有极佳的落地实践也欢迎交流。